Tutorial Dojo - DVA-C02 - Timed Mode Set 3
Test time: Dec 7 2023, 9h45 - 10h28 (00:47:24)
Score: 56/65 (86.15%)
- CDA – Development with AWS Services: 85.71%
- CDA – Security: 100%
- CDA – Deployment: 81.08%
- CDA – Troubleshooting and Optimization: 91.67%
Domain 1: Development with AWS Services
| No | Q | A | Ref | |
|---|---|---|---|---|
| 1 | ✅ | Replace spreadsheet-based tracking system. DynamoDB. | EDA: DynamoDB Streams + Lambda + SNS | |
| 2 | ✅ | Collect real-time user data | Kinesis Data Streams | |
| 3 | ❌ | API Gateway: Lambda Proxy integration | Recommend: Simple setup | |
| 4 | ✅ | CodeCommit, CodeBuild, CodeDeploy, CodePipeline. A central dashboard? | CodeStar | |
| 5 | ✅ | Cfn: Reuse value from a stack? | Outputs/Export & Fn::ImportValue | |
| 6 | ✅ | Hundreds of thousands of reads/writes per second. Which database? | DynamoDB | |
| 7 | ✅ | DynamoDB: Bidding system. | DynamoDB Streams + Lambda + Conditional Write | |
| 8 | ✅ | DynamoDB: Query a single table | LSI (when create the table) | |
| 9 | ✅ | DynamoDB: Throttled. Hot partition. Fix minimal effort? | Refactor to evenly distribute between partitions; Retries with exponential backoff | |
| 10 | ✅ | CodeCommit: Setup? | 1. Git credential - HTTPS (username/password); 2. SSH connection (SSH key-pair) | |
| 11 | ✅ | DynamoDB: 1.5KB. Write 100 items/s. WCU 100 but throttled. Fix? | Increase WCU to 200. | |
| 12 | ❌ | Deploy serverless app: Run C++ | Lambda doesn’t support C++ -> Create custom runtime | |
| 13 | ✅ | SQS: Duplicate message | SQS FIFO + SendMessage with DeduplicationID | |
| 14 | ❌ | SQS: postpone delivery messages to queue | Delay queue (not using visibility timeout) | |
| 15 | ✅ | ECS: Place task between AZs? | Spread | |
| 16 | ❌ | ECS: EC2. Task placement? | 1. Cluster constraint; 2. Task placement constraint; 3. Task placement strategy | |
| 17 | ✅ | Sync user data without your backend. | Cognito Sync (delegated use AppSync) | |
| 18 | ❌ | Kinesis Data Streams: Resharding, Scaling, and Parallel Processing | 1. One worker can process many shards. 2. Optimal ratio is 1 worker : 1 shard | |
| Enhanced Fan-out: stream consumers receive their own 2MB/second pipe of read throughput per shard | ||||
| 19 | ❌ | DynamoDB: Concurrency write | Optimistic Locking + Conditional Writes | |
| 20 | ❌ | DynamoDB: For each request, return WCU consumed (base table & GSI) | ReturnConsumedCapacity: | |
| 21 | ✅ | SQS: Config Dead Letter Queue | Just provide ARN of the queue to DeadLetterConfig | |
| 22 | ✅ | Elastic Beanstalk: Web app process large number of items from DynamoDB. Overload. Easiest fix? | Use Batch operations for Get, Put, Delete | |
| 23 | ✅ | DynamoDB: Send welcome mail for new user. How? | DynamoDB Streams + Lambda + SNS | |
| 24 | ✅ | DynamoDB: Table - FighterID (PK) - FilterTitle (SK). Query by other attributes? | Create a GSI | |
| 25 | ✅ | DynamoDB: + Elasticache. Write data if cache miss. Improve? | Add write-through + TTL | |
| 26 | ✅ | Kinesis Data Streams: 100 shards, Lambda (10 seconds/request, 50 items/seconds) | Maximum of 100 Lambda concurrency = number of shards | |
| 27 | ✅ | Cfn: How to automate the process of getting latest AMI? | Use System Managers Parameter Store | |
| 28 | ✅ | SQS: Process tool long & messages appear twice | Increase visibility timeout | |
| 29 | ✅ | CloudFront: Slow to login & 504 | Authentication@Edge + Origin fail over | |
| 30 | ✅ | Lambda: Increase CPU? | By increasing memory | |
| 31 | ✅ | API Gateway: Implement APIs form current Swagger spec. | Just import the OpenAPI/Swagger file. | |
| 32 | ✅ | Microservice using Docker + Fine-grain control | ECS | |
| 33 | ✅ | Quickly deploy Node app (provisioning, load balancing, ASG…) | Elastic Beanstalk | |
| 34 | ✅ | Amplify: config? | amplify.yaml | |
| 35 | ✅ | S3: Cross-Region Replication. Fail. Why? | Maybe Object Versioning is not enable | |
| 36 | ✅ | S3: Upload Terabytes of data from over the worlds. Slow. Improve speed? | S3 Transfer Acceleration | |
| 37 | ✅ | API Gateway: Reuse same function for different stage (different DynamoDB table) | Stage variable |
1.3 API Gateway API integration type
Choose an API Gateway API integration type
API Gateway - API integration types:
AWSLambda non-proxyintegration (Lambda customintegration): Need to specify how to map betweenmethod&integration
AWS ProxyLambda proxyintegration (Recommend): Simple setup- API Gateway maps the entire client request to the input
eventparameter of the backend Lambda function
- API Gateway maps the entire client request to the input
HTTPHTTP ProxyMock
1.16 ECS task placement
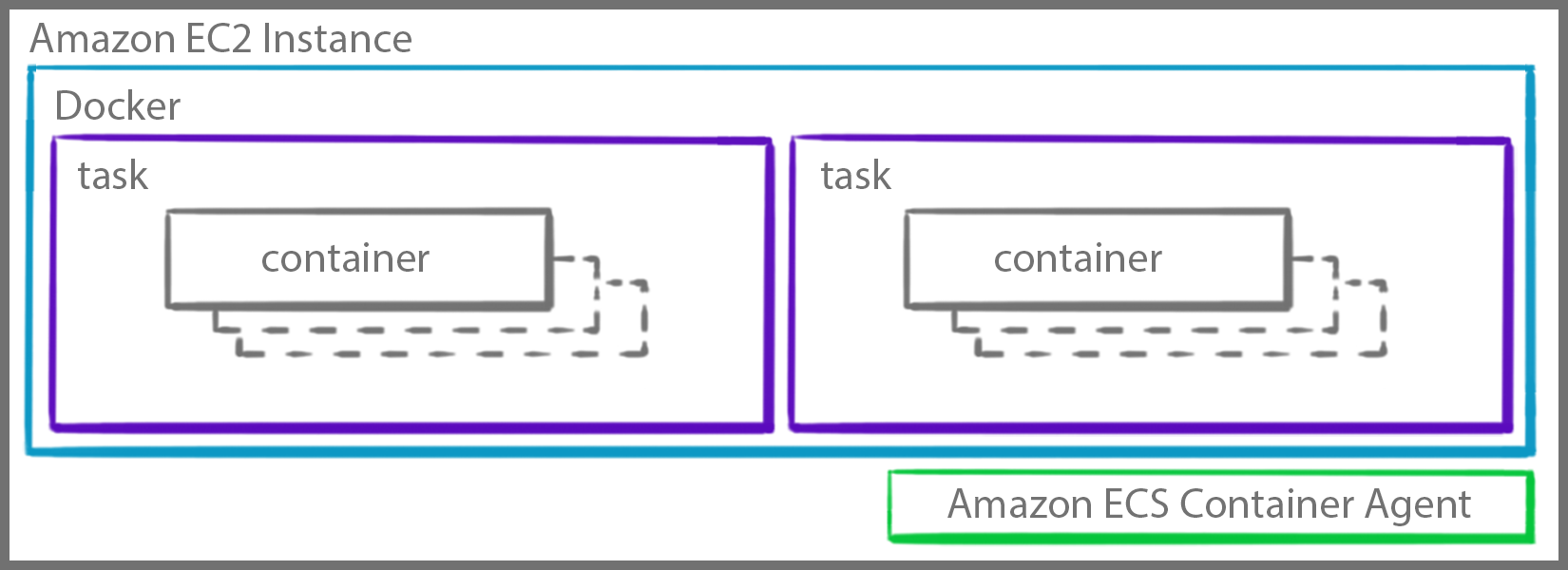
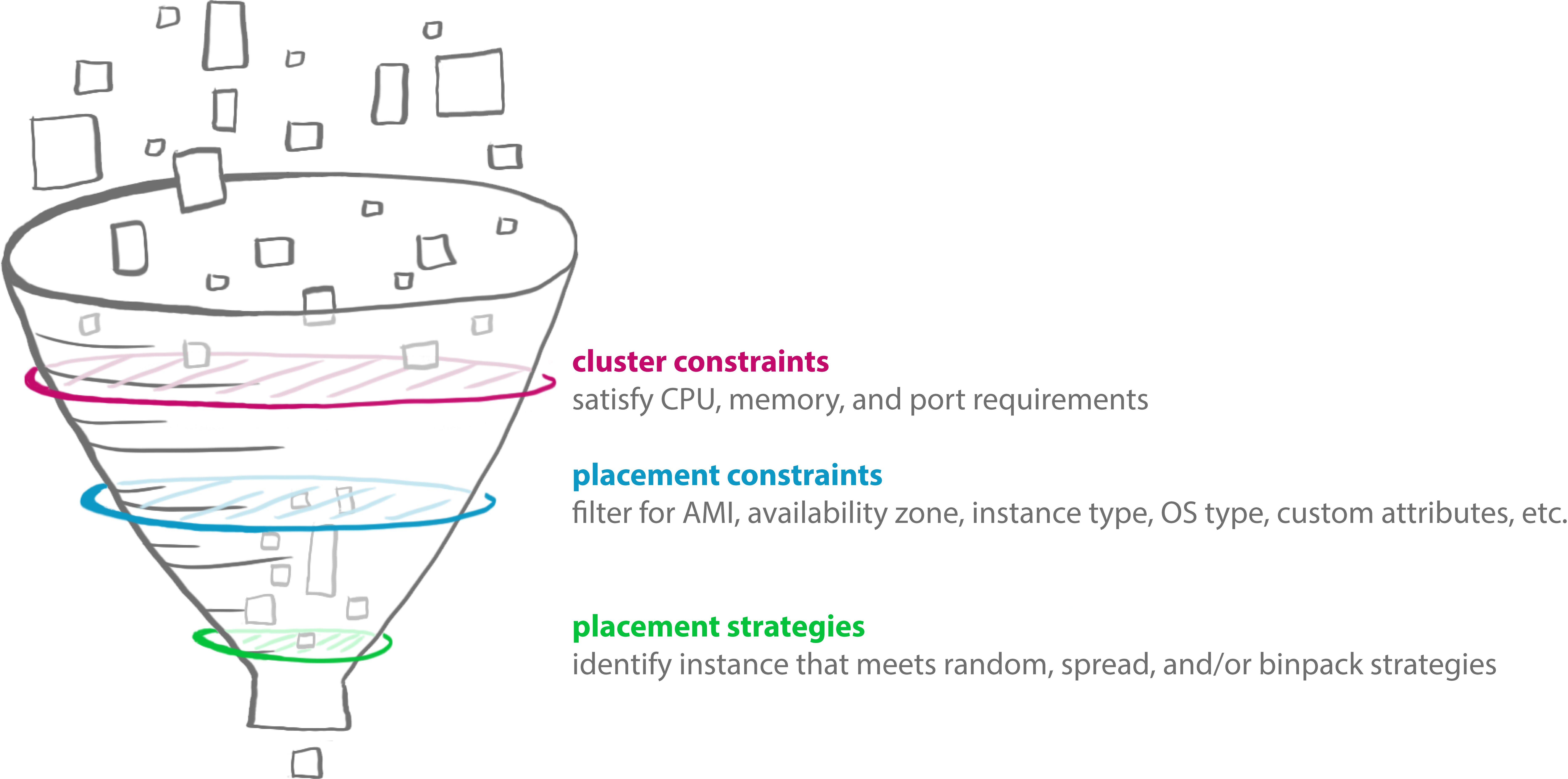 ECS Task Placement
ECS Task Placement
-
Task placement: Which container instances to place task?
-
“Cluster constraint”: Which one satisfy CPU, memory, port (in task definition)?
-
A task placement constraint is a rule that’s considered during task placement.
-
Constraint type
- distinctInstance
- memberOf
-
Expression: defined in
cluster query language(subject operator [argument])- Attribute:
- Build-in attribute:
e.g.
ecs.availability-zone,ecs.instance-type - Optional attribute:
- Custom attribute:
stack
- Build-in attribute:
e.g.
e.g.
attribute:ecs.availability-zone == us-east-1a - Attribute:
-
-
A task placement strategy is an algorithm for selecting container instances for task placement or tasks for termination: ECS supports 3 type of task placement strategy:
binpack: min unused CPU, memoryrandomspread: evenly based on- :
instanceId/host,attribute:ecs.availability-zone, …
- :
-
Ref:
- https://aws.amazon.com/blogs/compute/amazon-ecs-task-placement/
- https://docs.aws.amazon.com/AmazonECS/latest/developerguide/cluster-query-language.html
1.18 Kinesis Data Streams
https://aws.amazon.com/blogs/aws/kds-enhanced-fanout/
1.19 DynamoDB: Concurrency write
- Atomic Counter: 🛣️ Any one can writes (The database use the previous value)
- Optimistic locking & Conditional write: ⚠️ Many writes at a time (based on some condition)
- Pessimistic locking: 🛑 1 write at a time. Wait for your turn
Domain 2: Security
| No | Q hash-based message authentication code (HMAC) value of the encryption key in order to validate future requests. | A | Ref | |
|---|---|---|---|---|
| 1 | ✅ | API Gateway: Lambda authorizer - accepts header, query strings | Request parameter-based authorizer (REQUEST authorizer) | |
| 2 | ✅ | On-premise KMS, migrate to AWS. Key is store in dedicated hardware | CloudHSM | |
| 3 | ✅ | S3: Upload small file + Use KMS key: OK. Upload big file (100GB): not OK | AWS CLI use multipart upload for big files. It’s required the kms:Decrypt permission | |
| 4 | ✅ | S3: SSE with KMS (using default KMS key). Which header? | - x-amz-server-side-encryption: aws:kms | |
- Omit x-amz-server-side-encryption-aws-kms-key-id to use default KMS key for S3 | ||||
| 5 | ✅ | S3: SSE-C. How does it work? | 1. You manage key & give AWS the key each time you upload a file | |
1.1 x-amz-SSE-customer-algorithm/key/key-MD5 | ||||
| 1.2 If you lose the key, you lose the object | ||||
| 2. AWS handle encryption: | ||||
| 2.1 AWS store a hash-based message authentication code (HMAC) value of the encryption key in order to validate future requests. | ||||
| 2.2 When you need the object, you request the object (& provide the encryption key) | ||||
| 2.3 AWS decrypt & give you back the decrypted object | ||||
| 6 | ✅ | KMS: A file encrypted with data encryption key (DEK). How to decrypt the files locally? | 1. Use KMS’s Decrypt to decrypt the DEK | |
| 2. Use the plaintext DEK to decrypt the file (immediately erase the plaintext from memory after used) | ||||
| 7 | ✅ | CodeDeploy: Platform: ECS - appspec.yaml | appspec.yaml for ECS needs: TaskDefinition, ContainerImage, ContainerPort | |
| 8 | ✅ | Share DB connection endpoint | Systems Manager Parameter Store secure string | |
| 9 | ✅ | SSL certificate from 3rd party. Which service can store? | AWS Certificate Manager (for unsupported regions, use IAM certificate store) |
Domain 3: Deployment
| No | Q | A | Ref | |
|---|---|---|---|---|
| 1 | ✅ | EC2: EBS-backed root volume. How to detach the root-volume? | Stop the EC2 instance, then detach the root volume | |
| 2 | ✅ | Elastic Beanstalk: Maintain compute resource while deploying. No downtime. | Rolling with additional batch, Immutable | 3.2.1 3.2.2 3.2.3 |
| 3 | ✅ | DynamoDB: 3.5KB. 150 eventually consistent reads/second. How many RCU? | 1 strongly read -> 1 RCU | |
| 1 eventually read -> 0.5RCU => 150 -> 75 | ||||
| File 3.5KB -> 1:1 => 75 RCU | ||||
| 4 | ✅ | Lambda: Deployment package 80MB. What to do now? | Split the dependencies to a layer | |
| 5 | ✅ | SAM: How to use Cfn & include SAM? | Use Cfn Transform & AWS:Serverless macro to process SAM template to Cfn template | |
| 6 | ❌ | CodeDeploy deployment type (How the latest revision is deployed to instance?) | 1. In-place (EC2/On-Premises); 2. Blue/green | 3.5 |
| 7 | ✅ | Cfn: Different accounts. How to manage update across all accounts? | Use StackSets |
3.2 Elastic Beanstalk Deployment policies
- Deployment policies (aka deployment methods/strategies):
- AllAtOnce (Default)
- Rolling
- Rolling with additional batch
- Immutable
- Traffic splitting (aka Canary)
- Blue-green (with
Swap environment URLs)
3.6 CodeDeploy deployment type
Overview of CodeDeploy deployment types CodeDeploy concepts
CodeDeploy can deploy application to 3 platform (called deployment platform):
- EC2/On-Premises <= Needs CodeDeploy agent
- ECS
- Lambda
CodeDeploy make the latest application revision available on instance in a deployment group (a group of instances)
- In-place deployment: only support EC2/On-Premise
- Blue/green deployment
CodeDeploy supports 3 ways of routing traffic (via deployment configuration)
- All-at-once: 100%
- Canary: 2 increments: 10% + 90%
- Linear: n% x m times
3.7 StackSets vs nested stack vs cross-stack reference
StackSets: create stacks in AWS accounts across regions by using a single CloudFormation template- Nested stack: reuse a template in multiple Cfn template
- cross-stack reference: export values from one stack and use them in another (Output/
Export&Fn::ImportValue)
Ref:
- https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/stacksets-concepts.html#stacksets-concepts-stackset
- https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/using-cfn-nested-stacks.html
- https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/best-practices.html#cross-stack
- https://aws.amazon.com/blogs/aws/aws-cloudformation-update-yaml-cross-stack-references-simplified-substitution/
Domain 4: Troubleshooting and Optimization
| No | Q | A | Ref | |
|---|---|---|---|---|
| 1 | ❌ | Collect trace from multiple backends, AWS SDK, SQL queries… | AWS Distro for OpenTelemetry (supports collect from X-Ray) | |
| 2 | ✅ | X-Ray: Insufficient permissions to use X-ray console to view service map, segments. Which manged policy? | - AWSXrayReadOnlyAccess | |
| - AWSXRay | ||||
| - AWSXray | ||||
| 3 | ✅ | API Gateway: Fetch latest data without caching (using Cache-Control: max-age=0 header). Which permission? | Resource-based policy for execute-api:InvalidateCache action | |
| 4 | ✅ | DynamoDB: Streams, EventBridge + Lambda every 36 hours. Missing data? | DynamoDB Streams retention period is 24 hour. Only last 24 hours data is available | |
| 5 | ✅ | Kinesis Data Streams: Increasing data flow. Scale up? | Split-shard + (increase numbers of worker) | |
| 6 | ✅ | S3: CORS config: <AllowOrigin>, <AllowedMethod>, <AllowedHeader>, <MaxAgeSeconds>3600</MaxAgeSeconds> | MaxAgeSeconds: time in seconds that your browser can cache the response for a preflight request | 4.6 |
| 7 | ✅ | API Gateway: Lambda. 504. No errors in CW. Why? | Lambda function takes more than 30s (API Gateway timeout) | |
| 8 | ✅ | RDS: Slow response (in peak time). Already optimize queries. Resolve? | - Add Read Replica | |
| - Add caching with Elasticache | ||||
| 9 | ✅ | Latency-sensitive service. AWS Fargate, CloudFront, ALB. Too much unauthenticated users, increase CPU of Fargate. Fix? | Use CloudFront Function (attach to Viewer Request) to authenticate users | |
| 10 | ✅ | EC2: Monitor memory, swap. How? | Install CW Agent | |
| 11 | ✅ | Elastic Beanstalk: EC2. CW doesn’t show memory. Why? | By default, CW doesn’t track EC2 instance memory | |
| 12 | ✅ | Kinesis Data Steams: Producers restart -> Duplicate record. Fix? | Call PutRecord with SequenceNumberForOrdering param. |