Chap 0. Preface
This book DOES:
- Try to provide a definition of DevSecOps
- Provide pattern of success in DevSecOps
- Expose some of the technologies & practices involved in large DecSecOps deployments
This book DOESN’T:
- Provide a a comprehensive step-by-step guide to implementing DevSecOps
- Cover all software tools that an organization might use in DevSecOps
What Is DevSecOps?
DevSecOps is
- a set of agile & iterative practices that help to
- deliver software & technology systems rapidly, accurately, and repeatedly,
- emphasizing people & processes above
tools.
- emphasizing people & processes above
- deliver software & technology systems rapidly, accurately, and repeatedly,
- a culture
- testing & security is an extension of development
- automation & scripting is emphasize
DevSecOps allows people to
- use processes & tools to
- rapidly & repeatedly improve the quality of software.
Who Is This Book For?
Anyone interested in:
-
DevSecOps (& DevOps):
- maybe involved in development, security, operations or not
- have a computing background or not
-
the practices/processes in DevSecOps, e.g.
- write code, commit, push and have tests automated executing on that code
- scaling across multiple clouds seamlessly
How This Book Is Organized
-
Chap 1. The Need for DevSecOps
- How software was developed with methodologies like Waterfall, Agile?
- How software is developed with DevSecOps?
- The need to tear down department silos & places
- The important of culture in DevSecOps
-
Chap 2. Foundational Knowledge in 25 Pages or Less
- What you need to know to be successful in DevSecOps.
-
Chap 3. Integrating Security
- OWASP ZAP tool
-
Chap 4. Managing Code and Testing
- git, Gitflow pattern in DevSecOps
- Levels of testing
-
Chap 5. Moving Toward Deployment
- Configuration management as code
- Docker
- Build a local registry
-
Chap 6. Deploy, Operate, and Monitor
- Use Ansible, Jenkins for code building, deployment
- Monitoring & its best practices
-
Chap 7. Plan and Expand
- Kubernetes: Clustering & expanding the deployment in an organization
-
Chap 8. Beyond DevSecOps
- 5 patterns & takeaways from successful DevSecOps organizations
Chap 1. The Need for DevSecOps
Developing Software
A software development lifecycle (SDLC) has 4 phases:
- Gather Requirements
- Design Solution
- Develope Code (Implementation)
- Test Code (Verification)
In waterfall development:
-
Each stage needs to be completed before moving to the next phase:
- Gather requirements
- Design solution
- Develope code
- Test code
- Develope code
- Design solution
- Gather requirements
-
At the end of the requirements-gathering phase:
- The project has a scoped defined, includes all of the features of the software:
- functional requirements
- non-functional requirements
- If a new requirements is discovered during later states, it’s added by a following project or skipped.
- The project has a scoped defined, includes all of the features of the software:
-
The lag between the idea and the implementation can be months, or even years.
- Any competitive advantage can be evaporated.
Developing Agility
In order to rapidly delivery values to the skateholder, organizations have turned toward iterative processes like Agile, Scrum.
In iterative development:
-
Instead of define all requirements of all possible aspects of the projects, only the highest-value features are focused.
- These high features will come through a short SDLC of 2 to 4 weeks - an iteration (aka a sprint).
- If a requirements is missed, it can be added in the next iteration.
-
Market conditions can be rapidly response.
- You can focus on the missing features from the competitors.
-
There are a lot of ceremonies:
-
Sprint planning
-
Daily stand-up
-
Sprint review: the team shows up what it has accomplished (during that sprint).
-
Sprint retrospective: the team examines what might have been done differently (during that sprint).
The team might answers 3 questions:
- What should we start doing? (What the team might change?)
- What should we stop doing? (What doesn’t
work?) - What should we continue doing? (What work?)
-
Backlog grooming: the skakeholders (e.g. product owner) refine, re-priority the product backlog.
Type of backlogs
-
An overall backlog: list of all possible features to be tracked & prioritized
-
A sprint backlog:
- the commitment from the development team of which features to be implemented in the current iteration.
- created based on
- availability of team members
- their estimations of effort - level of effort (LOE) - for each individual item on the backlog.
-
-
The problem with software development, operating, security
Developing Broken Software
Why development teams develope broken software (software that doesn’t meets the requirements)?
-
Flawed requirements
-
Even if the original requirements was successfully obtained from the project sponsor.
-
Developing software in silo:
- The developers only interact within a silo - other developers.
- There is no communication between silos - developer teams, operation teams, security teams
The developers can only examine & interpret the requirements to the best of their ability.
-
Deadlines (timeline of the project) can force everyone to guess the requirements and sacrifice the quality.
The software development triangle
- Features
- Timeline
- Cost
A project can only choose 2 of 3 elements of the software development
-
Operating in a Darkroom
The operation teams
-
a.k.a networking administrators, system administrators, site reliability engineer (SRE), production engineer…
-
are responsible of deploying, operating, supporting the software in its production environment.
A software may
- run well on the local environment
- passed all the tests on the QA environment
But these environments are not the production environment - in which the operation teams need to deploy, operate, support the software.
Security as an Afterthought
In some organizations with the “ship at any cost” mentality, “minimum viable product” (MVP) altitude, the security is usually the first requirement to be sacrificed.
Security is hard, it must work every time, while an attacker only needs to be right once.
In DevSecOps, security is integrated early with the development cycle.
Culture First
The culture of the organization is the primary factor that determines whether DevSecOps will be successful.
-
A control-oriented, top-down organization will struggle to implement DevSecOps.
- These organization may use technology technology feels like DevSecOps, but without cross-team transparent, it’s very hard to success.
- In these organization, the
best solutionis less important than subordination & maintaining separation to keep control at the top.
-
DevSecOps facilitates a problem-solving approach, even if the solution comes from someone in a different department.
-
In DevSecOps, people work together across job functions, using the skills where needed.
The teams are transparent about their work, focusing on the end goal of accomplish useful work.
Job titlesare less important than work accomplishing.
Processes and People over Tools
Without the right culture, process & people, DevSecOps tools can slow down the development.
Promoting the Right Skills
-
Identify employees who have cross-functional experiences.
e.g.
- A developer who can deploy their own clusters, know the difference between DNS/DHCP.
-
Allow these employees to cross functional boundaries.
e.g.
- Developers will need access to, or at least visibility into, server and network areas that may have been solely under the purview of Operations.
- Operations and Security teams will need to have substantive early input within the project lifecycle so that they can provide feedback to improve downstream processes.
DevSecOps as Process
Hammers and screwdrivers
Tools are essential to complete some jobs efficiently.
- The tool should help complete the job, but the tool does not define the job.
DevSecOps tooling can provide huge efficiency gains when used by the right people.
important
Use the right tool
- for the right job
- in the right way.
Repeatability
DevSecOps focuses on
-
building repeatable process
-
facilitates automation
e.g.
- the creation of environments
- the deployment of codes
- the testing
by using the “as Code” paradigm:
- Infrastructure as Code
- Configuration as Code
- Policy as Code
- …
note
Everything as Code
- Manage as much as possible using source code management tools & practice e.g. git, git workflow
important
What is the benefit of “as Code”?
- Everything is committed to the history.
- Each commit is a version of the “Code”
tip
How can a repeatable deployment is possible
By using:
- same version of the configuration (GitOps)
- same version of software (CI/CD)
Visibility
DevSecOps enables visibility through out the development process:
-
Via agile ceremony: Daily Standup
-
Via tools:
Member of a DevSecOps team can
-
see exactly
- which deployment (configuration & software)
- in which environment.
-
make a new deployment in an environment as needed.
-
Reliability, speed, and scale
Repeatability & visibility leads to reliability.
- Code & environment can be deployed consistently (repeatability).
- If there is an error, it is found (& fixed) immediately (visibility).
And there come:
- speed - the ability to quickly react to changing needs.
- scale - because of repeatable deployment.
Microservices and architectural features
With microservices:
- Small functional area of code are separated and can be on their own, called a microservice.
- Each microservice
- provides a consistent API - e.g as a HTTP web service - to other microservices in the whole system.
- can be developed & deployed separately, which also increasing speed & momentum.
The DevSecOps SDLC
| Dev | DevOps | DevSecOps | |
|---|---|---|---|
| 3. Develope Code - Implementation (Dev) | 1. Code | (Dev) | + Security |
| 2. Build | Continuous Integration | + Security | |
| 4. Test Code - Verification (QA) | 3. Test | Continuous Integration | + Security |
| 4. Release | Continuous Delivery: Approval Gates | + Security | |
| 5. Deploy | Continuous Deployment | + Security | |
| 6. Operate | (Ops) | + Security | |
| 7. Monitor | (Ops) | + Security | |
| 1. Gather Requirements 2. Design Solution | 8. Plan | + Security |
- DevOps SDLC closely reflects what actually happens for software development.
- DevSecOps SDLC: security is a part of every phase.
Summary
DevSecOps comes as a natural progression of software development.
- DevSecOps try to break down development silos (barriers between teams).
Cultural changes, from the top of an organization, is the primary key to achieve the most benefit from DevSecOps.
With the right culture, process, people, an organization can use DevSecOps tools to facilitate:
- repeatability
- visibility
- reliability
- speed & scale
Chap 2. Foundational Knowledge in 25 Pages or Less
The Command-Line Interface
Command Line - Terminal - Shell
terminal (terminal simulator)
: a program that provides a textual user interface
: - reads characters from the keyboard & displays them on the
screen
: - handle escape code (aka escape sequence), e.g. Ctrl + C
: e.g.
: - OS’s defaults: MacOS Terminal, GNOME Terminal, Command Prompt (Windows)
: - 3rd-party: iTerm2, Windows Terminal
: - New generation that use GPU: Alacritty, Kitty, Warp
shell
: a program that run inside the terminal:
: - acts as a command interpreter
: - handles input/outputs (IO) via streams (stdin, stdout, stderr)
: - provides: variables (e.g. $SHELL), built-in commands (e.g. ls, cd)
: e.g.
: - sh: Bourne shell
: - bash: Bourne again shell
: - Modern, human-friendly shells: zsh, fish
: - Windows: MS-DOS, PowerShell
Why Do I Need the Command Line?
- Speed (with enough practice)
- The CLI tools can do things GUI tool can’t do.
Getting Started with the Command Line
Shell’s Streams
When performing I/O, a system call refer to an open file using a file descriptor - a (usually small) nonnegative integer.
Open files are regular files or pipes, FIFOs, sockets, terminals, devices.
Each process has its own set of file descriptors:
-
Including 3 standard file descriptions:
File descriptor Purpose stdiostream0Standard Input stdin1Standard Output stdout2Standard Error stderr -
These 3 standard file descriptor are opened on the process’s behalf (by the shell), before the process is started.
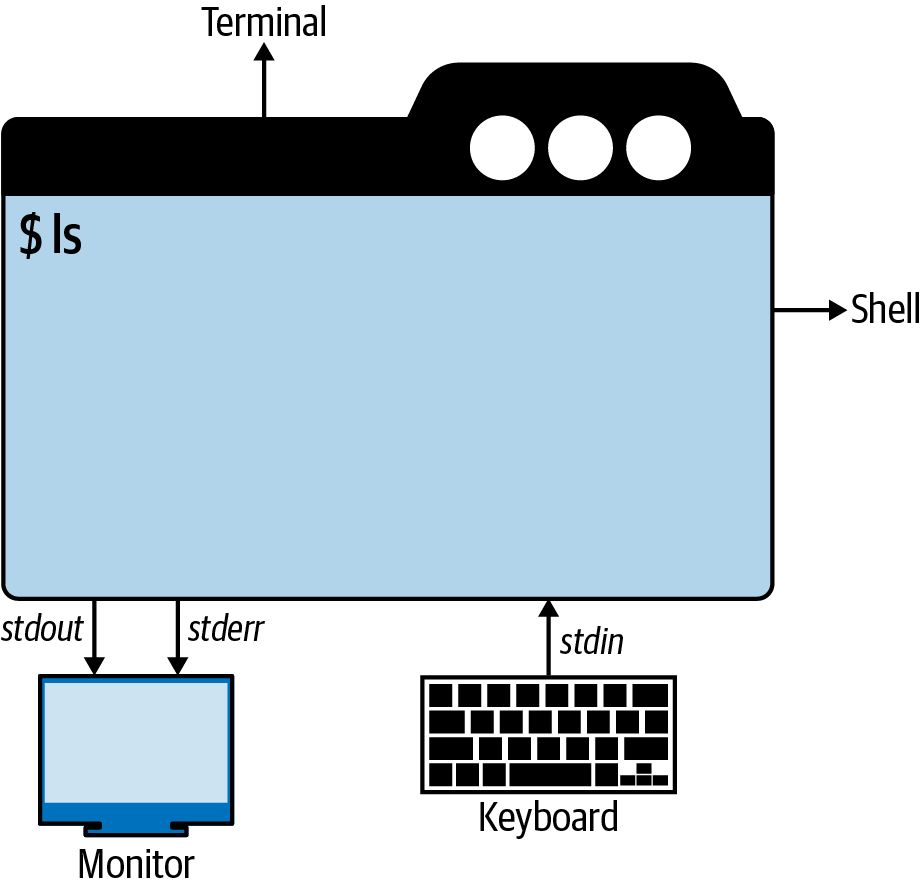
tip
More precisely,
-
In a non-interactive shell, the program inherits copies of the shell’s file descriptors.
The shell normally operates with these three file descriptors always open
-
In an interactive shell, these 3 file descriptors refer to the terminal under which the shell running.
Protocols: A High-Level Overview
protocol (communication protocol) : When multiple parties communicate, a protocol is an agreement on how each party will act
Computers are built around conformance to protocols to ensure interoperability.
The internet are built on common, shared & open protocols:
- Internet Protocol suite (TCP/IP)
- OSI model
Protocol Layers
- TCP/IP protocol: 4 layers
- OSI model: 7 layers
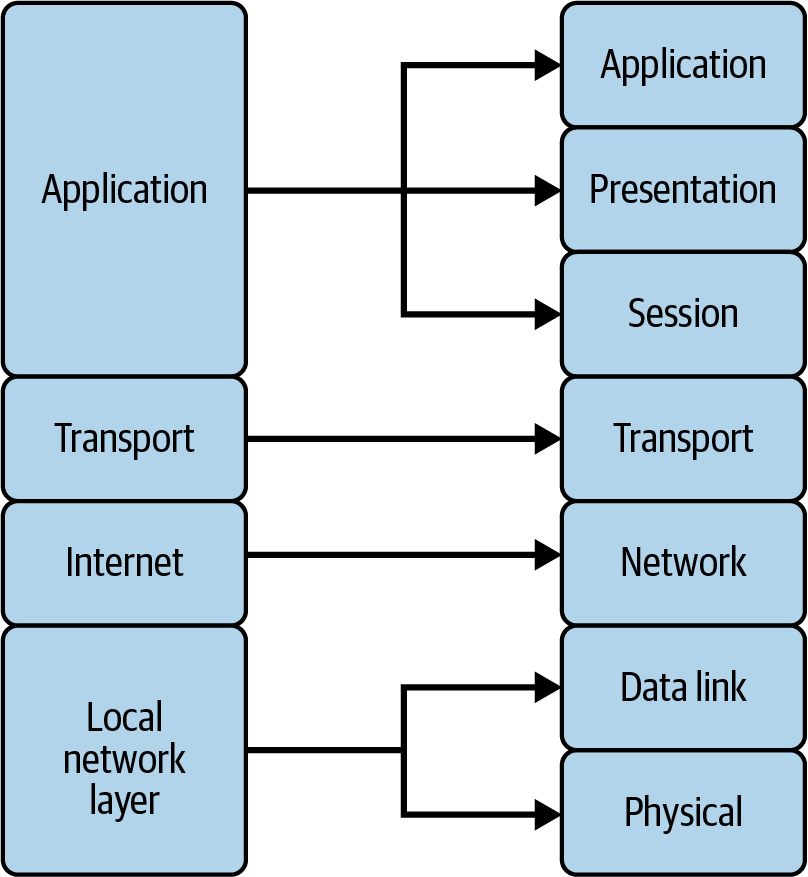
When devices communicate over a network, the data is passed down the layers
- from an application e.g. a web browser
- eventually onto a physical medium e.g. wired Ethernet or radio signals for WiFi.
The receiver then passes the data up through the layers to the corresponding application on the receiving side.
note
Protocol Wars (Internet–OSI Standards War) Which communication protocol would result in the best and most robust networks?
- Internet protocol suite (TCP/IP)
- OSI model
The winner is TCP/IP. (OSI model is still used as a reference for teaching, documentation, cloud computing)
Two Protocols Plus Another
TCP (Transmission Control Protocol) : connection-oriented : applications receive packets in an orderly sequence
UDP (User Datagram Protocol) : connection-less : applications receive packets in an un-orderly sequence : - ensuring that packets have arrived : - asking for retransmission when packets have not arrived
ICMP (Internet Control Message Protocol)
: Used by ping command
: - The ping command sends Echo Request, (ICMP message type 8)
: - The device under test responds with Echo Reply, (ICMP message type 0)
Basic Internet Protocols
DNS
Domain name system
DNS (domain name system) : What? A naming system for computers, resources… in the Internet : Analogy? Phone book of the internet : - Name -> Phone Number : - Domain Name (aka hostname) -> IP Address : How? Delegates the responsibility of assigning domain names & mapping those names to Internet resources by designating authoritative name servers for each domain
The Internet maintains two principal namespaces:
- the domain name space (aka domain name hierarchy)
- the IP address spaces (IPv4, IPv6)
The Domain Name System
- maintains the domain name space
- provides translation services between the domain name space and the address spaces
note
DNS isn’t just any naming system: it’s the internet’s standard naming system as well as one of the largest distributed databases in the world.1
important
DNS is also a client–server system:
- DNS clients querying DNS servers to retrieve data stored in that distributed database.
- Because the database is distributed, DNS servers will often need to query one or more other DNS servers to find a given piece of data.
DNS clients are often called resolvers, whereas DNS servers are sometimes called name servers.
Resolvers ask DNS servers for information about particular indexes into the distributed database.1
Domain name space, DNS zones
The domain name space consists of a tree data structure:
-
Each node (or leaf) in the tree has a label and zero or more resource records (RR), which hold information associated with the domain name.
-
The tree sub-divides into zones:
-
A DNS zone may consist of as many domains and subdomains as the zone manager chooses.
-
Administrative responsibility for any zone may be divided by creating additional zones.
Authority over the new zone is said to be delegated to a designated name server. The parent zone ceases to be authoritative for the new zone.
-
-
The tree begins at the root zone (a single dot
.) -
The second level of zones:
- Top-level domain (TLDs):
- Generic TLDs (gTLDs):
com,org,net,edu… - Country-code TLDs (ccTLDs):
us,uk,vn…
- Generic TLDs (gTLDs):
- Top-level domain (TLDs):
-
DNS servers can load zone data from:
- zone data file (aka master files)
note
A DNS server that loads information about a zone from a zone data file is called a primary DNS server for that zone.
- other DNS servers via a mechanism called a zone transfer
note
A DNS server that loads information about a zone from another DNS server using zone transfer is said to be a secondary DNS server for that zone.
The DNS server from which the secondary DNS server transfers the zone is referred to as its master DNS server.
Both the primary and secondary DNS servers for a zone are said to be authoritative for the zone.
note
DNS is a distributed database:
- indexes (domain names)
- partitions of the database (zones)
tip
DNS can also be partitioned according to class.
- The only class we need to know is
IN(Internet)
Domain name
The domain name itself consists of the label, concatenated with the label of its parent nodes on the right, separated by a dot (.).
-
e.g.
example.comexample: DNS node’s label.: separatorcom: parent node’s name
-
The right-most label conveys the top-level domain (
TLD)e.g. the domain name
example.combelongs to the TLDcom. -
The hierarchy of domains descends from right to left; each label to the left specifies a subdivision, or subdomain of the domain to the right.
e.g.
- the label
exampleis a subdomain of thecomdomain - the label
wwwis a subdomain ofexample.comdomain
- the label
DNS limitations
- The domain name space (hierarchy) may have up to 127 levels.
- A label may contain 63 characters.
- The full domain name may contain 253 characters (other 2 octets are for the length of the domain name)
- The character may be in a subset of ASCII character set - LDH rule:
- Letter:
a-z,A-Z(The domain names are case-insensitive interpreted) - Digit:
0-9 - Hyphen:
-
- Letter:
note
Can a domain name contain Unicode characters?
An application can use domain name that has Unicode characters via Internationalizing Domain Names in Applications (IDNA) system, in which:
- The application (e.g. web browser) can map Unicode characters to valid DNS character set using
Punnycode.
Domain registration
Each TLD is delegated to a registrar to managed that DNS zone.
Domain (within a TLD) is registered within the desired TLD, according to the rules ot the registrar (of that TLD).
When a domain name is registered, control of the sub-domain within that domain is delegated to the registrant (the person/organization who registered the domain with the register of that TLD)
- The
registrantneeds to provide at least 2 authoritative name server, which response to DNS query for sub-domain of that domain name.
DNS Resource Records
tip
DNS is a distributed database:
- indexes (domain names)
- partitions of the database (zones)
What is the data?
Data in DNS is stored in units of resource records (RR).
Resource records come in different classes and types.
-
The
classeswere intended to allow DNS to function as the naming service for different kinds of networks.In practice DNS is used only on the internet and TCP/IP networks, so just one class,
INfor internet, is used. -
The
typesof resource records in the IN class specify both the format and application of the data stored-
Some of the most common resource record types in the
INclassRR Type Description Function AIPv4 Address Maps a domain name to a single IPv4 address AAAAIPv6 Address Maps a domain name to a single IPv6 address CNAMECanonical Name (Alias) Maps a domain name (the alias) to another domain name (the canonical name) MXMail Exchanger Names a mail exchanger (mail server) for an email destination NSName Server Names a name server (or DNS server) for a zone PTRPointer Maps an IP address back to a domain name SOAStart of Authority Provides parameters for a zone -
Overview of all active DNS record types
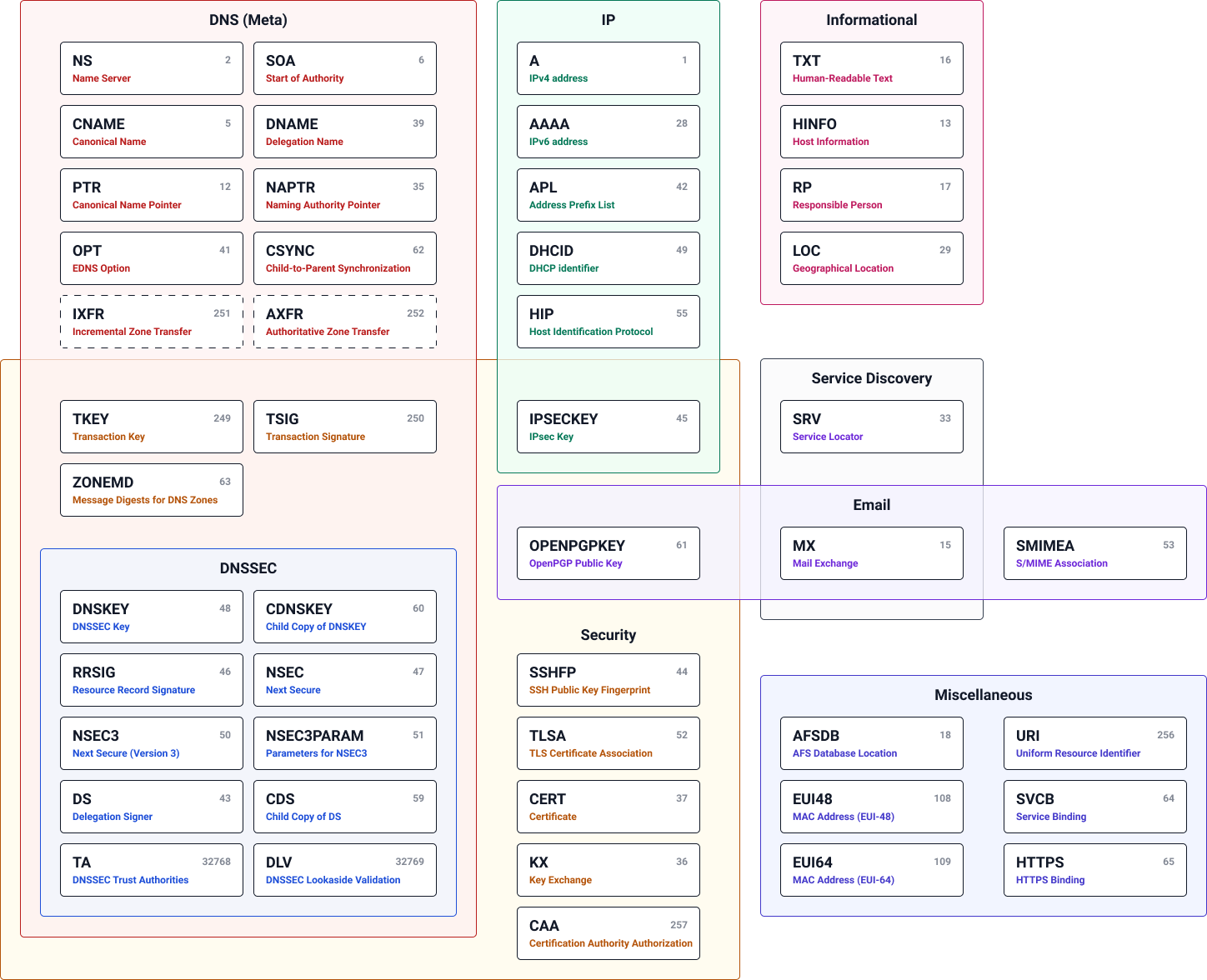
-
Resource Records are in master file format which including 5 fields [NAME] [TTL] [CLASS] TYPE RDATA.
| RR Field | Function | Note | Example |
|---|---|---|---|
[NAME] | [Optional] The domain name to which this resource record is attached | Can be: - a fully qualified domain name ( FQDN - ended in a dot - .) - or a relative domain name (doesn’t end in a dot) | @ (the origin - by default is the domain name of the zone). (the root)www (relative) |
[TTL] | [Optional] The time-to-live (TTL) value for the resource record, which governs how long a recursive DNS server can cache the record | TTL can be specified by: - a 32 bit integer number of seconds - or use scscaling factorsaling factors, e.g. s, h, d, w, as a suffix | - 86400- 86400s, 24h, 1d- 1h30m |
[CLASS] | [Optional] Class field is almost always IN - default. | There are also CH, HS | |
TYPE | aka type mnemonics - will be translated to a numeric type code | ||
RDATA | Data for that RR type | For each RR type, RDATA stores record-specific data (in a particular format) |
important
Each resource record can only map a domain name to a single RDATA field.
To map a domain name to multiple RDATA fields, you can create multiple resource records with the same NAME (aka a resource record set)
e.g.
-
All zones has a
NSRRSet with at least 2NSRRsexample.com. 72186 IN NS a.iana-servers.net. example.com. 72186 IN NS b.iana-servers.net.google.com. 6626 IN NS ns1.google.com. google.com. 6626 IN NS ns3.google.com. google.com. 6626 IN NS ns2.google.com. google.com. 6626 IN NS ns4.google.com. -
amazon.comzone has aARRSet with 3ARRsamazon.com. 628 IN A 52.94.236.248 amazon.com. 628 IN A 54.239.28.85 amazon.com. 628 IN A 205.251.242.103
Hostname resolution
Resolution
tip
In Vietnamese, Domain Name System means hệ thống phân giải tên miền. What is the extra phân giải? It’s resolution.
For a host - with a valid IP address - to communicate on a network, the host needs to translate the friendly name (domain name) to an IP address.
-
First, it examines a locally file called
hostse.g.
-
Linux/Mac:
/etc/hosts## # Host Database # # localhost is used to configure the loopback interface # when the system is booting. Do not change this entry. ## 127.0.0.1 localhost 255.255.255.255 broadcasthost ::1 localhost -
Windows:
%SystemRoot%\System32\Drivers\etc\hosts
-
-
If the destination computer is not defined in the
hostsfile, the DNS is queried next (by DNS resolvers).
DNS resolution (by DNS resolvers)
Domain name resolvers determine the domain name servers responsible for the domain name in question by a sequence of queries starting with the right-most (top-level) domain label.
-
The resolution process starts with a query to one of the root servers.
-
In typical operation, the root servers do not answer directly, but respond with a referral to more authoritative servers,
e.g., a query for “www.wikipedia.org” is referred to the org servers.
-
The resolver now queries the servers referred to, and iteratively repeats this process until it receives an authoritative answer.
 The diagram illustrates this process for the host that is named by the fully qualified domain name “www.wikipedia.org”.
The diagram illustrates this process for the host that is named by the fully qualified domain name “www.wikipedia.org”.
important
Each device that receives an IP address typically also receives one or more DNS servers that act on behalf of those devices to obtain hostnames from other DNS servers.
-
The IP can be “received”
- manually with an assigning
- automatically with Dynamic Host Configuration Protocol (DHCP) …
-
The DNS server can be included or not
- (A host can receive an IP address without an DNS server and communicates without issue)
- These DNS servers are known as
DNS resolvers
note
DNS resolver vs DNS authoritative
-
DNS resolver: (aka recursive resolution, recursive resolver, DNS iterator…)
- responsible for obtaining the answers to queries from client devices
- not responsible/authoritative for the domain in question
-
DNS authoritative:
- responsible/authoritative for one or more domains
- answer the queries
DNS cache servers - TTL
To improve efficiency, reduce DNS traffic across the Internet, and increase performance in end-user applications, the Domain Name System supports DNS cache servers which store DNS query results for a period of time determined in the configuration (time-to-live - TTL) of the domain name record in question.
The DNS cache servers is also known as recursive server
- Typically, such caching DNS servers also implement the recursive algorithm necessary to resolve a given name starting with the DNS root through to the authoritative name servers of the queried domain.
- Typically, Internet service providers (ISPs) provide recursive and caching name servers for their customers.
- In addition,
- many home networking routers implement DNS caches and recursion to improve efficiency in the local network.
- you can maintain your own DNS resolvers, e.g. Bind9, CoreDNS, PiHole, Adguard Home
- you can use a DNS services (public DNS resolvers), e.g. Google Public DNS (
8.8.8.8), CloudFlare DNS (1.1.1.1)
Client DNS lookup
Users generally do not communicate directly with a DNS resolver. Instead DNS resolution takes place transparently in applications such as web browsers, e-mail clients, and other Internet applications.
- When an application makes a request that requires a domain name lookup, such programs send a resolution request to the DNS resolver in the local operating system, which in turn handles the communications required.

note
The DNS resolver can also be an authoritative DNS server.
Split-horizon DNS
A split-horizon DNS (aka split DNS, split-view DNS) provides different set of DNS records, selected by the source of the DNS request.
Start of Authority and time-to-live
Each DNS zone contains a Start of Authority (SOA) record that defines domain metadata.
| Field | Field Name | Description | Note |
|---|---|---|---|
MNAME | Primary master name server for this zone | ||
RNAME | Email address of the administrator responsible for this zone (encoded as a name) | The “@” symbol in the email address is replaced with a dot (“.”)e.g. dns-admin.google.com. is encoding of dns-admin@google.com | |
SERIAL | Serial number | An integer value that is incremented for each change to the zone | |
REFRESH | Refresh interval (s) | The interval that the secondary DNS server waits before asking for updates | |
RETRY | Retry interval (s) | The interval that the secondary DNS server should wait between requests to an unresponsive server | |
EXPIRE | Expiration interval (s) | The interval that a primary DNS server can be down before it is no longer considered authoritative for the domain | |
TTL | Negative-caching interval (s) | The interval that a negative or not-found answer should be cached before a recursive server checks again |
- The serial number and the refresh, retry, and expiration intervals are all related to zone transfers
tip
SOA fields and zone transfer
-
After each refresh interval, a secondary DNS server for a zone checks with its master DNS server (often the zone’s primary) to see whether the master’s serial number for the zone is higher than the secondary’s.
If the master has a higher serial number, the secondary requests a copy of the latest version of the zone with a zone transfer.
-
If the check fails for some reason, the secondary keeps checking with the master at the retry interval (usually shorter than the refresh interval) until it successfully learns whether it needs a new version of the zone.
-
And if the checks fail for the entire expiration interval (usually several refresh intervals), the secondary assumes its zone data is now out of date and expires the zone.
After expiring the zone, a secondary will respond to queries in the zone with a Server Failed response code.
- The negative-caching TTL specifies to other DNS servers how long they can cache negative responses from this zone’s authoritative DNS servers.
HTTP
HTTP (HyperText Transfer Protocol) : the language of the web : used for transferring web pages & remote programmatic access between services
HTTP is a stateless protocol
- When the client - e.g. your computer - makes a request to a web server that speaks HTTP, the server does not remember one request to the next; each request is new
A HTTP message consists of:
control dataheaderscontent(aka body, payload)trailers
For more information, see
- RFC 2616: HTTP/1.1 - HTTP Message
- RFC 9110: HTTP Semantics - Message Abstraction
- RFC 9113: HTTP/2 - HTTP Control Data
note
In a HTTP message, control data can be sent as:
- the
start lineof a message (in HTTP/1.1 & earlier) (akastart line, , )- For a request message, it’s the
request line, e.g.POST / HTTP/1.1(METHOD TARGET_URI PROTOCOL_VERSION) - For a response message, it’s the
status line, e.g.HTTP/1.1 403 Forbidden(PROTOCOL_VERSION STATUS_CODE STATUS_REASON)
- For a request message, it’s the
pseudo-header fieldswith a reserved name prefix (in HTTP/2 & HTTP/3), e.g.:authority
note
The Host header was added to HTTP version 1.1 as a means to host multiple websites on a single IP address.
HTTPS
HTTP uses TCP connections as the transport layer.
-
HTTP is the top layer in a “protocol stack” of “HTTP over TCP over IP”.
-
When HTTP wants to transmit a message, it streams the contents of the message data, in order, through an open TCP connection.
- TCP takes the stream of data, chops up the data stream into chunks called
TCP segments, and transports the segments across the Internet inside envelopes calledIP packets. - Each TCP segment is carried by an IP packet from one IP address to another IP address.
- TCP takes the stream of data, chops up the data stream into chunks called
HTTPS, a secure variant of HTTP, inserts a cryptographic encryption layer (called TLS or SSL) between HTTP and TCP.
- In additional to the TCP connection (of the transport layer), HTTPS also has a TLS connection to encrypt the data.
Other protocols
File Transfer Protocol(s) (FTP)
- FTP, SFTP (Secure FTP)
- FTPS (FTP over SSL)
- SCP (Secure Copy Protocol)
Secure Shell (SSH)
A DevSecOps operation will use SSH to configure servers remotely.
tip
Knowing how to use SSH keys and port forwarding would be quite helpful.
Simple Network Management Protocol (SNMP)
The monitoring infrastructure that can appear within a DevSecOps team might use SNMP.
Data Security: Confidentiality, Integrity, & Availability (CIA)
Confidentiality
: ensures that only specific, authorized individuals can view, modify, or share this guarded information.
: applies to both data in transit (traversing a network) & data at rest (in storage)
tip
Data in use: memory
Integrity : ensures that data is maintained in a known-good state
Availability : ensures that business-related data is available to the organization, partners, or end-users whenever & wherever
Development Overview for Scripting
Shell Commands: Built-in & External
built-in commands
: built-in the shell
: executed directly (by the shell), without invoking another process
: e.g. pwd, cd
external commands
: exist regardless of the shell
: invoked in a separate environment (another process) that cannot affect the shell’s execution environment.
: e.g. ls, cp
important
Some builtin commands are also available as an external command
e.g. /usr/bin/pwd, /usr/bin/cd
tip
To check if a command is builtin or external, use type -a
e.g.
$ type -a cd
cd is a shell builtin
cd is /usr/bin/cd
note
To see the list of builtin commands in the shell:
- Bash’s builtins:
bash -c "man cd" - Zsh’s buildins:
man zshbuildins
For more information, see
Basic Bash Constructs: Variables, Data, and Data Types
| Syntax | Example | Note | |
|---|---|---|---|
| Create a variable | var=value | username=bob | Variables in Bash have no type |
| Access a variable | $var | echo $username | Use dollar sign $ to access a variable |
| Create a constant variable | readonly var=value | readonly username="alice" |
Making Decisions with Conditionals
if statement
In Bash, if statement “test” if a command succeeds
-
e.g.
if [ -z "$BASH_VERSION" ]; then echo "Bash is required to interpret this script." fi[ EXPRESSION ]Exit with the status determined by EXPRESSION.-z "$BASH_VERSION"Test if the length of STRING is zero
e.g. Hello world
name="Bob"
if [[ $name == "" ]]; then
echo "Hello, world"
else
echo "Hello, $name"
fi
-
Syntax
If If - else If - elif - else if TEST_COMMANDS; then CONSEQUENT_COMMANDS; fiif TEST_COMMANDS; then CONSEQUENT_COMMANDS; else MORE_CONSEQUENTS; fiif TEST_COMMANDS; then CONSEQUENT_COMMANDS; [elif MORE_TEST_COMMANDS; then MORE_CONSEQUENTS;] else ALTERNATE_CONSEQUENTS; fi1 - If
TEST_COMMANDSsucceeds,CONSEQUENT_COMMANDSlist is executed(When
elifs are present)2 - If
TEST_COMMANDfails, eacheliflist is executed in turn,- if
MORE_TEST_COMMANDSsucceeds, the correspondingMORE_CONSEQUENTSis executed and the command completes.
(When
elseis present)3a - If the final command - in
TEST_COMMANDS- fails,ALTERNATE_CONSEQUENTSis executed.
(When
elseis present)3b - If the final command - in the final
elifclause - fails,ALTERNATE_CONSEQUENTSis executed.
e.g.
if true; then # Do something fie.g.
if false; then # Unreachable code else # Do something fie.g.
OS="$(uname)" if [[ "${OS}" == "Linux" ]]; then echo "this script is running on Linux" elif [[ "${OS}" == "Darwin" ]]; then echo "his script is running on MacOS" else echo "unsupported OS: only support on macOS and Linux" fi - if
-
Use case
In other programming language,
ifworks a little different then in Bash.-
In Go,
ifspecify the conditional execution of two branches according to the value of a boolean expression. -
In Bash,
ifspecify the conditional execution of two branches according to theexit status2 of the test commands.The test commands can be:
-
warning
When if is used with [ or [[,
- it looks like an
ifstatement in other languages, - but it doesn’t work exactly like an
ifstatement in other languages.
[ and test command
-
The
[- left bracket - is a builtin command, synonym fortest- builtin command. -
[ortest:- considers its arguments as comparison expressions or file tests
- returns an exit status corresponding to the result of the comparison/test:
- if the comparison/test is true,
[succeeds (returns 0) - if the comparison/test is false,
[fails (returns non-zero status)
- if the comparison/test is true,
note
About [ vs ]
[: build in command]: last argument of[, to match the opening[
[[ - extended test command
- The
[[…]]is extended test command, which performs comparisons in a manner more familiar to programmers from other languages.
note
Bash sees [[ … ]], e.g. [[ $a -lt $b ]], as a single element, which returns an exit status.
-
Using the
[[…]]test construct, rather than[…]can prevent many logic errors in scripts.- No word splitting or filename expansion takes place between
[[and]] - The
&&,||,<, and>operators work within a[[]]test, despite giving an error within a[]construct. - Arithmetic evaluation of octal / hexadecimal constants takes place automatically within a
[[]]construct.
- No word splitting or filename expansion takes place between
Conditional expressions
-
Bash conditional expressions
Category Conditional Expressions Meaning Note Unary Test a file -e fileTrue if file [e]xists -d fileTrue if file exists and is a [d]irectory. -f fileTrue if file exists and is a regular [f]ile. -r fileTrue if file exists and is [r]eadable. -w fileTrue if file exists and is [w]ritable -x fileTrue if file exists and is e[x]ecutable. Test a string -n stringorstringTrue if the length of string is [n]on-zero. -z stringTrue if the length of string is [z]ero. Binary Compare strings string1 == string2True if the strings are equal. string1 != string2True if the strings are not equal. string1 < string2True if string1 sorts before string2 lexicographically testuses ASCII orderingstring1 > string2True if string1 sorts after string2 lexicographically [[…]]use the current localeCompare numbers arg1 OP arg2true if arg1 is OPto arg2, respectively.For the full list of conditional expressions, see Bash Reference Manual - Bash Conditional Expressions
-
Bash conditional expression supports 6 arithmetic operator
-eq-ne-lt-le-gt-geequal to not equal to less than less than or equal to greater than greater than or equal to
Looping
A loop is a block of code that iterates a list of commands as long as the loop control condition is true.
Bash supports 3 types of loops: for, while, until.
for
for loop run a set of commands for each item in a list.
-
Syntax
for <name> in <words> do <commands> done -
Example
for item in ~/effective-shell/* # Loop through all items in a folder do echo "Found: $item" # Print the item's full path to the screen doneOutput
Found: /home/dwmkerr/effective-shell/data Found: /home/dwmkerr/effective-shell/docs Found: /home/dwmkerr/effective-shell/logs Found: /home/dwmkerr/effective-shell/pictures Found: /home/dwmkerr/effective-shell/programs Found: /home/dwmkerr/effective-shell/quotes Found: /home/dwmkerr/effective-shell/scripts Found: /home/dwmkerr/effective-shell/templates Found: /home/dwmkerr/effective-shell/text Found: /home/dwmkerr/effective-shell/websites
See, Effective Shell - For loop
while
A while loop iterates through a block of code only when a condition remains true.
If the condition isn’t true to begin with, the while loop will never execute the code within.
See, Effective Shell - While loop
until
The until loop is like the while loop except that the code will only be executed when a condition remains false.
If the condition is true to begin with, then the code within the until loop will never execute
See, Effective Shell - Until loop
Arrays
-
Arrays are variables that can store multiple values.
-
An array is created by using the equals symbol and putting the array values in parenthesis.
days=("Monday" "Tuesday" "Wednesday" "Thursday" "Friday" "Saturday" "Sunday") -
Once you have defined your array you can retrieve an element at a given index by using the square bracket notation shown below:
echo "The first day is: ${days[0]}" # Monday echo "The last day is: ${days[6]}" # Sunday
caution
In Bash, arrays start at index zero. In Zsh, arrays start at index one.
Summary
https://learning.oreilly.com/library/view/learning-coredns/9781492047957/ch02.html#idm45327686781144
exit status is aka return status, exit code, status code
.
Every command returns an exit status.
- A successful command returns a 0
- An unsuccessful one returns a non-zero value that usually can be interpreted as an error code
In Bash, a command:
- succeeds if its
return status5 is zero -0. - fails if its
return statusis non-zero, e.g.1,2,3…
Chap 3. Integrating Security
In DevSecOps,
-
security is an integral element contained within each step of the software development lifecycle.
-
the processes & tools for security are available to all members of a DevSecOps team (rather than only of the security team)
Integrating Security Practices
-
Some processes & tools that should exists regardless of DevSecOps
- Patch, update process
- Thread modeling; identification of attack vector, model
- Security training
- Compliance for legal/regulation requirements
- Disaster recovery (DR) policies, responses, recovery
-
Some processes & tools for DevSecOps
- Least privilege
- Role-based authentication
- Key-based, certificate-based authentication
- Code traceability
Implementing Least Privilege
Everyone should have only enough - no more, no less - permissions to handle their tasks.
e.g.
- Granting the minimum rights needed for database users
- Read records
- Create new record
- Some software requires elevated permissions to be installed, but day-to-day work doesn’t need these permissions
warning
Least privilege can be frustrating at times, because of the context switching required when a developer finds that they can’t access certain data.
File permissions in Linux
File permissions in Linux is the answer to
- 1️⃣ who?
- 2️⃣ can do what?
In Linux:
-
Every file has 6 permission modes (aka file mode) (👈 2️⃣ do what?)
-
3 normal modes:
read,write, andexecutablePermission File Directory Read Read the content of the file. Read the names of files in the directory. Write Modify & delete the file. Create, rename & delete files in the directory. Execute Execute the file (if the user also has read permissions on it) Access file information in the directory:
- change into it (cd)
- list its content (ls). -
3 special modes: the
sticky bit,setuid, andsetgid.
-
-
Every file has 3 types of class (ownership category):
user,group, andother. (👈 1️⃣ who?)The class of a file specifies the ownership category of users who may have different permissions to perform any of the above operations on a file.
File class The ownership category of users Notes User The user that own the file aka ownerGroup The group that own the file, has one or more members Other The category for everyone else aka world
When files are created, they are usually given:
-
the
owner: the current user -
the
group: group of the directory the file is inBut this varies with the operating system, the file system the file is created on, and the way the file is created.
You can change the
- owner and group of a file by using the
chownandchgrpcommands. - permissions of a file by using the
chmodcommand.
note
When using chmod, the permissions can be specified in symbolic notation or octal notation
| Permission (👈 2️⃣ do what?) | Symbolic notation | Octal notation |
|---|---|---|
| Read | r | 4 |
| Write | w | 2 |
| Execute | x | 1 |
File permissions in action
-
e.g.
$ ls -la /etc/hosts -rw-r--r--. 1 root root 538 Mar 2 15:13 /etc/hosts -
A
file permission bits- e.g.-rw-r--r--.- specify- the scope of permissions (👈 2️⃣ who?)
- the type of access (👈 1️⃣ do what?)
| Prefix | File permission bits (aka file mode bits) | Suffix | |
|---|---|---|---|
| Example | - | rw-r--r-- | . |
rw- r-- r-- | |||
| Purpose | File type | Each permission bit is represent: | Additional permission features |
- -: regular file | - In symbolic notation by 3 characters. | - .: SELinux context | |
- d: directory | - or in octal notation by a octal number. | - +: ACL | |
| - … | - @: extended file attributes |
Symbolic notation
| The | 1st triad | 2nd triad | 3rd triad |
|---|---|---|---|
| … is the permission bit for file class of … | user | group | other |
| Example | rw- | r-- | r-- |
In symbolic natation, each permission bit is present by 3 characters:
- First character represent
readpermission:rif reading is permitted,-if it is not. - Second character represent
writepermission:wif writing is permitted,-if it is not. - Third character represent
executepermission :xif execution is permitted,-if it is not.
Numeric notation (aka octal notation)
In numeric notation, the file mode bits is represent by 4 octal digits (0-7), derived by adding up the bits with values 4, 2, and 1
| Example | File mode bits | First digit | Second digit | Third digit | Fourth digit |
|---|---|---|---|---|---|
| Bit values | 4: set-user-ID bit | 4: read | The same values | The same values | |
2: set-group-ID bit | 2: write | ||||
1: restricted deletion or sticky attributes. | 1: execute | ||||
| Anyone can do anything | Numeric: 777 | 7 | 7 | 7 | |
Symbol: rwxrwxrwx | rwx | rwx | rwx | ||
Numeric: 755 | 7 | 5 | 5 | ||
Symbol: rwxr-xr-x | rwx | r-x | r-x | ||
Numeric: 644 | 6 | 4 | 4 | ||
Symbol: rw-r--r-- | rwx | r-- | r-- |
Using chmod to change file permission modes
The chmod command supports both type of permission notation:
- For symbolic notation,
chmodcan add/remove/set permissions of each individual file class (or all file classes). - For numeric notation,
chmodcan set permissions of:- all file classes
- some trailing classes (by ignoring leading digits)
Role-based access control (RBAC)
RBAC : granting permissions based on the role (or job duties). : ~ group-based permissions (no more granting permissions to individuals) : no more revoking all permissions of someone leaving
e.g.
- A hiring manager can access to data about candidates, salaries… of someone hired into a developer role.
- A developer
- doesn’t need to (& can’t) access to these data.
- need to access to the development server…
Security for authentication process
-
Don’t you a permanent credential, e.g. password
- use a short-term or/and revokable credential, e.g. token
-
If you must use a password:
- Don’t use the same password for many accounts.
- Don’t remember the password by heart, use a password manager - e.g.
1Password,Bitwarden- try your best to secure it. - Instead of using only password:
- Use multi-factor authentication:
- OTP from an app, a physical key.
- Use Passkey
- Use multi-factor authentication:
-
When using SSH protocol to connect to a remote server:
- Instead of using SSH key-pair
You can
- Prevent someone from using your SSH key-pair (A public-private key-pair can be protected with a username/password)
- Prevent a host - that has the SSH key-pair - e.g. your computer - from connecting to a remote host, e.g. instead of your server, it’s the attacker server
- Use short-live certificate that’s signed by a Certificate Authority (CA).
- Instead of using SSH key-pair
You can
Maintaining Confidentiality
Data in Flight
HTTPS, DoH
-
Instead of using HTTP (HTTP over TCP/IP) - and sending unencrypted data (as plaintext).
- Using HTTPS (HTTP over TLS over TCP/IP) that has an extra TLS connection to encrypt the data (using asymmetric cryptography).
note
No mailing post-card, only mailing letter.
note
HTTPS is like using Enigma machine to encipher your messages. Even if someone opens it, they still cannot read the real messages.
- Using DNS over HTTPS (DoH) (from a centralized DNS resolvers, e.g. Google, CloudFlare, instead of from ISPs) to protect privacy.
note
No one should know you’re surfing Reddit, Facebook, some NSFW pages, whether it’s your boss, the IT guys, or the Big Brother.
Eavesdropping on email
For email,
-
To transfer email (between servers), there is SMTP - Simple Mail Transfer Protocol
-
To receive email (on end-user devices), there are
- POP3 - Post Office Protocol v3
- IMAP - Internet Message Access Protocol
-
These protocols are all un-encrypted - just like HTTP - but can integrated with TLS to add encryption.
Transfer files
- Secure Shell (SSH) is encrypted by default.
- File Transfer Protocol (FTP) needs to add the encryption layer.
Wired versus WiFi versus offline
Data traverses a wired network is less likely to eavesdropping than a wireless network (Wifi, Cellular/LTE).
An attacker can capture the traffic over wireless network (Physical layer), but they still need to break the layer on top (TLS) to decrypt the HTTP traffic.
Data at Rest
After transferred through the network, data will be at rest - in a storage, e.g. disks, USB drives, backup tapes…
Data at rest needs to be
-
encrypted at:
- Hardware level
- OS level
- Database level
- File level
-
using standard ciphers, e.g. Advanced Encryption Standard (AES)
caution
Remember, these standard ciphers still can be brute-force attack with enough computing resource and time.
- Time-sensitive data is not a big problem if attackers success.
- But long-lived data - Social Security, medical record,… - may cause problematic.
Data in Use
Data in use needs to be protect by best-effort of patching CVEs and preventing supply-chain attacks.
Verifying Integrity
An attack on integrity may take a long time before found.
- To verify integrity, in additional to the data, there need to be a verifiable source of original truth.
- If an attacker can approach the source of original truth, they can change the data integrity without being notice.
Checksums
hash function
: a function that can be used to map data of arbitrary size to fixed-size values (hashed string)
: ~ checksum function, e.g MD5, SHA-1,SHA-256, SHA-384, SHA-512
checksum ~ one-way hashed : take a data, e.g. a file/string; execute a checksum function on it will return a checksum
important
A checksum:
- is unchanged for a specific dagta
- has a fixed length no matter the size (this length is depended on the algorithm of the hash function)
tip
Fingerprint -> A Person Hashes string -> File/String
warning
A matched checksum doesn’t guarantee 100% that the file/string hasn’t been corrupt/altered.
- There may be collisions.
Verifying Email
SDP - Sender Policy Framework ~ (IP check)
: Ensures the sending mail server is authorized to originate mail from the email sender’s domain
: ~ Is the mail’s sender matched with the sender server?
: e.g.
: - A mail that claims it’s from example.com, needs to be sent from 1.2.3.4 IP address
tip
A mail that claims it’s from you, needs to be sent from your home's address.
The collect postman check if the mail’s sender address matched the house address?
DKIM - DomainKeys Identified Mail ~ (Domain check)
: Allows the receiver to check that an email that claimed to have come from a specific domain was indeed authorized by the owner of that domain
: ~ Is the mail sealed & has the sender signature?
: e.g.
: - A mail that claims it’s from example.com needs to have a public key for example.com
tip
A mail that claims it’s from you needs to be sealed and has your signature
The deliver postman check if the mail’s has its sender signature?
DMARC 1 - Domain-based Message Authentication, Reporting, and Conformance : Give email domain owners the ability to protect their domain from unauthorized use (email spoofing)
tip
Someone is sending fake mails in your name, what do want to do with those mails?
caution
All 3 protocols: SPF, DKIM, and DMARC rely on DNS to function.
If your DNS infrastructure is exploit, attackers can:
- Add IP to SPF
- Change the signature to their
- Change the policy of DMARC
Providing Availability
To increase availability, the single points of failure needs to be eliminated.
With the advent of cloud computing, the cost of providing availability in computing has decreased:
- Deployments in multi-cloud providers, in multi-regions is achievable.
Service-Level Agreement (SLA) and Service-Level Objectives (SLOs)
SLA - Service-Level Agreement : PROMISE: The agreement you make to your clients, end users : External : e.g. : - How much downtime is acceptable during a period (a month/quarter/year)? : - Monthly Uptime Percentage of no less least 99.9%
SLOs - Service-Level Objectives : GOAL: The objectives your team must hit to meet that agreement : Internal : e.g. : - Each services must a lot less than SLA - 99.99%, 99.999%
SLIs - Service-Level Indicator : MEASURE: The real indicator about the performance : External & Internal : e.g. : - Customer looks to SLI to demand a refund.
Defining SLA
Identifying Stakeholders
stakeholders : who paid for the app: : - so the app can be developed: have direct influence on the decisions about the app & it’s availability : - so they can use it: need to be represented by user groups, internal customer services
Identifying Availability Needs
The availability needs can be
-
provided:
- directly by the stakeholders
- indirectly via interviews/meetings
-
gathered through observation (more accurate)
note
Regardless of the method, you should verify back with the logs (traffic/request logs).
caution
The seasonal and cyclical activities should be included when identifying availability needs.
e.g. A monthly report run at the end of a month/quarter may be missed by everyone.
important
But what exactly availability means?
- Which level?
- Network: IP
- Transport: TCP
- Application: HTTP
- How long is latency?
How do you know that the system has that availability? Monitoring, observation.
important
Evaluation criteria of a monitoring software:
- Protocols
- Complexity of the check
- Alerting
- Scaling
- …
Estimating Costs
The cost for availability may increase exponentially.
| The level of availability | % uptime | Downtime per year | Downtime per day | ||||
|---|---|---|---|---|---|---|---|
| (day) | (hour) | (min) | (hour) | (min) | (sec) | ||
| One 9 | 90% | 36.5 day | 2.4h | ||||
| Two 9s | 99% | 3.65 day | 14m | ||||
| Three 9s | 99.9% | 0.365 day | ~ 9h | 1.4m | |||
| Four 9s | 99.99% | ~ 1h | 55m | 9s | |||
| Five 9s | 99.999% | 5.5m | 0.9s | ||||
| Six 9s | 99.9999% | 0.5m | 0.09s |
What About Accountability?
accountability : Who did what & when did they do it?
In computing, these info are available via logging.
For Linux, logging is handled by:
syslog: old system, easy to use but hard to scale.systemd: new system, plain-text at/var/log.
note
There are a lot of things needs to be done with log:
- Monitor the logs in realtime
- Import log entries to a database
- Automatically archive old logs
Site Reliability Engineering (SRE)
The main goal of SRE is providing visibility & transparent throughout the SDLC,
This is done by:
- Monitoring
- Logging, log analysis
caution
Monitoring & logging can
- decreased performance of the system.
- increase cost:
- doing monitor
- store the logging
To balance the cost and the amount of logs, you can:
- Use feature flag to indicate the level of log
- Ensure the applications, services supports
- changing its functions depends on the feature flag without restarting/re-initializing.
- monitoring automatically when deployed (e.g. Using Ansible)
note
With feature flag, an CI/CD system can quickly enable/disable features of the applications.
note
How much monitoring should we have?
As much as we can get:
- It still depends on the type of services, the longevity of each nodes.
- But more metrics is better than not enough metrics.
Code Traceability and Static Analysis
Code Traceability
code traceability (Programming) : tracing a line of code backward through the source code management history to the original change request that caused the developer to write it
code traceability (Testing) : step through the code line by line, watching in-memory data as it changes
code traceability (DevSecOps) : step through the code to validate & verify its operation: : - use build-time flags & feature flags to add more debugging instrumentation & logging : - e.g. A microservice is slow
Static analysis and code review
static analysis (static program analysis) : analysis of computer programs performed without executing them : e.g. linter, CVEs scanner…
dynamic program analysis : analysis of computer programs performed by executing them : e.g. function testing, code coverage, fuzzing, concurrency errors, performance analysis…
code review : review process to adherence to the coding style & quality standard of an organization
Static analysis and code review can identify these kind of issues:
-
Errors & bugs (unexpected behaviors)
-
Maintaining issues
e.g. Ternary may be prohibited
-
Security issues
e.g. The code run as expected, but a user can see other users’s resources.
-
CVEs
-
Compliance & Regulation issues
important
Static analysis tools can be integrated at:
- Local environment:
- While developing: code changed
- Before CI: code committed/pushed
- CI/CD:
- Before merged
Compliance & regulatory issues
Any organization needs to act in compliance with the regulation.
caution
False positives: a test result incorrectly indicates the presence of a condition.
Static analysis can have false positives, which can cause a lot of overhead.
Becoming Security Aware
Computer security problems can be traced back to 2 major reason:
- Lack of awareness (from developers, operations…)
- Lac of time imposed by often-artificial deadlines.
Finding Formal Training
Security training is available at many forms:
- On-site
- Virtual
- Classroom
- Hand-ons
Ideally, an organization can have training that is customized to the organization needs & its technology (programming languages, infrastructures…)
There are also generalized training & certificates from
- SANS Institute
- ISC2:
- Certificates
- CC – Certified in Cybersecurity - an entry level certificate
- CISSP - Certified Information Systems Security Professional - is the gold standard for security certifications
- Certificates
Obtaining Free Knowledge
- OWASP Top 10: a standard awareness document for developers and web application security
- OWASP Cheat Sheet Series: simple good practice guides for application developers that the majority of developers will actually be able to implement.
Input valid
Developers who integrate security into the development process assume that all input/external data
- is incorrect, e.g. empty data, too long…
- may have been entered with malicious intent
All data needs to be valid:
- on the client but still give good UX.
- on the server
Enlightenment Through Log Analysis
Servers are under attack all the times, there are bot attacks that scan for:
- Open ports
- CVEs
- Default password
By examining log files, you can get enlightenment about the type of attacks.
Practical Implementation: ZAP
Why ZAP?
Zed Attack Proxy (ZAP) is cross-platform software used for vulnerability scanning of web applications.
tip
Zed Attack Proxy ZAP (its website is zaproxy.org) is originally an project from OWASP, but has join Software Security Project (SSP) - an initiative of the Linux Foundation.
ZAP provides a graphical interface and trivially easy method to scan for common problems highlighted on the OWASP website.
Additional functionality is freely available from a variety of add-ons in the ZAP Marketplace, accessible from within the ZAP client.
What is ZAP?
At its core, ZAP is what is known as a man-in-the-middle proxy.
ZAP:
- stands between the tester’s browser and the web application
- will:
- intercept, inspect messages sent between browser and web application
- modify the contents if needed
- forward those packets on to the destination.
See:
Who can use ZAP?
ZAP provides functionality for a range of skill levels – from developers, to testers new to security testing, to security testing specialists.
Where ZAP can run?
ZAP supports
- Major OS: Linux, Windows, Mac
- Docker
- CI: GitHub Actions
See https://www.zaproxy.org/download/
ZAP in action
warning
A scan by ZAP can be interpreted as an attack.
You should
- scan only targets that you have permission to test.
- also check with your hosting company and any other services such as CDNs that may be affected before running a ZAP scan.
Creating a Target
We’ll use OWASP Juice Shop - a demo web app encompasses vulnerabilities from the entire OWASP Top Ten along with many other security flaws found in real-world applications!
caution
Don’t use someone public web application as a target of your ZAP test, you may go to jail.
Juice Shop can runs
- on a variety of platforms: including Node.js, Docker, and Vagrant,
- or as an instance on Amazon Web Services (AWS) Elastic Compute Cloud (EC2), Azure, or Google Compute Engine
tip
A ruining instance of the latest version of OWASP Juice Shop is available at: http://demo.owasp-juice.shop
warning
The demo instance is a deployment-test and sneak-peek instance only! You are not supposed to use this instance for your own hacking endeavors! No guaranteed uptime! Guaranteed stern looks if you break it!
Installing ZAP
Getting Started with ZAP
ZAP Mode
Safe: no potentially dangerous operations permitted.Protected: (Default) you can only perform (potentially) dangerous actions on URLs in the scope.Standard: does not restrict anything.ATTACK: new nodes that are in scope are actively scanned as soon as they are discovered.
See https://www.zaproxy.org/docs/desktop/start/features/modes/
Manual Scan
Automation Scan
Summary
- Integrate security throughout DevOps to create DevSecOps.
- CIA triad and security.
- Zed Attack Proxy (ZAD).
Chap 4. Managing Code and Testing
As in [[chap-01#The DevSecOps SDLC]], we’ve known that Dev, Built, Test is three steps of the DevOps SDLC
Examining Development
For high-level programming design and architectural, you can look for
- books published by O’Reilly.
- books written by Marin Fowler
[!NOTE] > TCP/IP Illustrated series by W. Richard Stevens are good books for networking.
Be Intentional and Deliberate
Write code that
- is easy to read and maintain.
- doesn’t introduce technical debt.
note
Technical debt implied cost of future reworking required when choosing an easy but limited solution instead of a better approach that could take more time
question
Hard-coding values & magic numbers: What and when? %% TODO: Research this %%
Don’t Repeat Yourself
According to Wikipedia, “Don’t repeat yourself” (DRY) is
- a principle of software development
- aimed at reducing repetition of information which is likely to change,
- replacing it with abstractions that are less likely to change, or
- using data normalization which avoids redundancy in the first place.
In Pragmatic Programmer, DRY principle is “Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.”
If the same value is used in different places,
- Give it a name (don’t hard-coding it).
- Instead of directly using the values, using the name.
caution
If the same value are in different places, ask whether they’re the same purpose, before DRY?
tip
Don’t apply DRY to everywhere and at any times.
- Some developers will try their best to remove duplication in code.
- There is a proverb in Golang, A little copying is better than a little dependency.
- There are also WET, AHA…
Managing Source Code with Git
note
There are a lot of Versicion Control System (VSC): CSV, SVN, Mercurial, Git…
See https://en.wikipedia.org/wiki/Version_control#Version_control_software
note
VCS is aka is Source Code Management (SCM) system
Git is the most popular SCM for now (with the raising of open-source software and GitHub)
Git - a distributed version control system (DVCS)
Git is a distributed VCS:
- clients don’t just check out the latest snapshot of the files; rather, they fully mirror the repository, including its full history.
- every clone is really a full backup of all the data.
The distributed nature of Git allow a vast ranges of workflow for your project and your team:
- Centralize workflow: one repository can accept code, everyone synchronizes their work with it e.g. Most closed source software use this workflow
- Integration-Manager workflow:
- each developer (contributor)
- has write access to their own public repository & read access to everyone else’s.
- send a request to the maintainer of the main repository
- the maintainer - adds the contributor’s repository as a remote & merge locally - pushed merged changes to the main repository e.g. GitHub’s fork (feature) & open-source software
- each developer (contributor)
- Dictator and Lieutenant workflow:
- contributor
- works on their topic branch
- rebase on top of
master
lieutenant: merges contributor’s topic branch into lieutenant’s master branchdictator: - merges lieutenant’s master branch into dictator’s master branch - push dictator’s master branch to master remote repository e.g. Big project: Linux
- contributor
Git on the server
To collaborate in Git, you’ll need a remote Git repository, which everyone can
- have access to
- push to, pull from
warning
Technically, you can push/pull changes directly to a repository on another Git client.
But don’t do it! It will be a nightmare!
Git remote repository
A remote repository is generally a bare repository - a Git repository that has no working directory.
note
You can get a bare repository with:
git initgit clone --bare
After run these two commands, you’ll get a repository with only the .git directory.
Git’s transfer protocols
Git supports 4 protocols to transfer data (to a remote repository)
- Local protocol
- HTTP/s
- Secure Shell (SSH)
- Git
Local protocol
Git use Local protocol when the remote repository is
- in another directory on the same host
- in a shared file system
e.g.
- Clone a local repository
$ git clone /srv/git/project.git- withoutfile://- Git uses hardlinks or directly copy the files it needs$ git clone file:///srv/git/project.git- withfile://
warning
When you specifies file://, Git fires up the processes that it normally uses to transfer data over the network, which is less efficient
Use file:// when import from another VCS
- Add a local repository to an existing Git project
$ git remote add local_proj /srv/git/project.git
HTTP/s
Git can communicate over HTTP using 2 modes:
- Dump HTTP - prior to Git 1.6.6
- Smart HTTP - from Git 1.6.6
Dumb HTTP
Dumb HTTP serves the bare Git repository like normal files from the web server.
- You
- put the bare Git repo under the HTTP document root
- set up a post-update hook
- Anyone can access the webserver can also clone the repo.
Smart HTTP
Smart HTTP
- works similarly to SSH but can run over standard HTTPS port
- can use various HTTP authentication mechanisms e.g. username/password: easier for the user than SSH keys
- can setup to both:
- serve anonymously like
git://protocol - push over with authentication, encryption when needed e.g. An anonymous user can read the repo, if they need to write to the repo, it will require authentication.
- serve anonymously like
note
With Smart HTTP, the user can:
- use a single URL for all type of access
- use username/password (without having to generate SSH keys locally, then update public key before able to do anything)
- use it anywhere (HTTP/s ports are open anywhere)
warning
- Git over HTTPS can be a little more tricky to setp up compare to SSH
- When using Git over HTTP, by default the user needs to enter password everytime he/she need to interact with Git server:
- This can feels a little frustrated, and more complicated than SSH
- The user can use the OS’s credentials caching tools - e.g. MacOS Keychain, Windows Credential Manager - to solve this problrem
Secure Shell (SSH)
tip
SSH access to servers is
- usually already set up in most places
- if it isn’t, it’s easy to do
For example, to clone a Git repo over SSH
- using
ssh://URL$ git clone ssh://[user@]server/project.git - using shorter scp-like syntax
$ git clone [user@]server:project.git
tip
If user@ is not specified, Git assumes the user you’re currently logged in as.
| Pros | Cons |
|---|---|
| - SSH is easy to setup (on the server) - SSH is secure (data is encrypted & authenticated) - SSH is efficient (data is compressed before transfered) | - SSH doesn’t support - Even a read-access (to the repo) need to have SSH access (to the machine) |
note
SSH Protocol can use HTTPS port (443), which is call SSH over HTTPS, but it’s still SSH.
Git
Git protocol
- is a special daemon that comes with Git
- listens on port
9418- similar to port
22of SSH
- similar to port
- unsecured
- a repo is available publicly (with full access) or is not available
| Pros | Cons |
|---|---|
| - Fastest network transfer protocol | - Unsecured - Attacker can do a man-in-the-middle attack and insert malicious code to the repo - Unauthenticated - Most difficult to set up - Require its own daemon - Require firewall access to port 9418 |
note
The URL for Git protocl is git://
warning
A Github’s repo may have URL begins with git, but in fact it’s SSH protocol.
e.g. git@github.com:facebook/react.git
- The prefix
gitis the user at thegithub.comserver - The suffix
.gitis the convention that indicates a directory is a git bare repository
A Simple Setup for Git
Set up a Git server
We’ll go through the process of setup a Git server with some assumptions:
- The server is at
git.example.comwith a repository namedmy_projectat/src/git - The repositories on the server are stored at
/srv/git- The project is
my_project, whose bare repository is at/src/git/my_project.git
- The project is
- You have SSH access to the server as a user named
user
Get a bare repository of the Git repository
On your local machine, you’ll to get a bare repository of my_project repository:
- Use
git clone --baregit clone --bare my_project my_project.git - Or use
cp(there will be some minor differences in the configuration file)cp -rf my_project/.git my_project.git
Putting the bare repository on a server
Use scp command to copy files between hosts using the Secure Copy Protocol over SSH:
scp -r my_project.git user@git@example.com:/srv/gitShare the remote repository with other peoplegit init --sharedGit with automatically add group write permissions to the repository
note
At this point, other users who have SSH-based access to the srv/git directory on that server with:
- read permission can clone your repository with:
git clone user@git.example.com:/srv/git/my_project.git
- write permission can push to your repository with:
git push
Setup up user management
You can control access to your repository by:
- using SSH access Anyone that have SSH access (read/write) to the server can also access the repository
- using the server OS file-system permission
Using SSH access
When using SSH access as the user management for your Git server, you can:
- Create user accounts for everyone
- And run
adduser, set temporary passwords for every new user.
- And run
- Create a single
gituser account on the Git server- Add SSH public keys of all people that have write access to
~/.ssh/authorized_keys
- Add SSH public keys of all people that have write access to
- Have your SSH server authenticate from an LDAP server or an other centralized authentication source.
How SSH Key works
Public-key cryptography:
- Public-key cryptography, or asymmetric cryptography, is the field of cryptographic systems that use pairs of related keys.
- Each key-pair consists of a public key and a corresponding private key
- In a public-key encryption system,
- anyone with a public key can encrypt a message, yielding a ciphertext
- but only those who know the corresponding private key can decrypt the ciphertext to obtain the original message.
- Security of public-key cryptography depends on keeping the private key secret; the public key can be openly distributed without compromising security. SSH and public-key cryptography:
- SSH uses public-key cryptography to authenticate the remote computer and allow it to authenticate the user, if necessary. e.g. - The SSH server - keeps the public key of any host that want to have access to it. - If a host has the private key corresponding to a public key on the SSH server, that host can access to the SSH sever. Setup authenticate with a SSH key-pair:
- Check if there’s one existed at
~/.ssh - If not, generate one:
- On Linux/Mac, use
ssh-keygen
- On Linux/Mac, use
Using OS file-system permission
Using Git (Briefly)
When using Git to manage source code, the basic workflow looks like
| Step | Command | Description |
|---|---|---|
| Init repo | git init | Initializes a new Git repository |
| Clone repo | git clone | After you clone the repo, you’ll have:
|
| Write code | When you write code, you’re making changes to the working copy | |
| Commit code | git add | Add the changes to the staging area (stage a file for commit) |
git commit | Commit the staged changes (as a snapshot) to the local repository | |
| Push code | git push | Pushes the committed snapshots to the remote repository |
| Merge code | git merge | Merges code when collaborating with other developers |
note
You can use git commit -a to commit all modified and deleted files without adding them to staging area.
Commit code: Record changes to the repository
Git knowledge about working tree’s files
Each file the working area can be in one of 2 states:
- untracked: file that Git doesn’t know about
- tracked: file that Git knows about & has the status of :
- unmodified (committed) (tracked file that is not modified)
- modified (tracked file that is modified)
- staged (staged file ready for commit)
- ..
Git concepts
| Term | Alternative names | What is it? What does it mean? |
|---|---|---|
| Working copy | working directory, working tree, workspace | Everything in the repository directory except .git |
| Staging area | index | |
| Local repository | history | |
| Remote repository | sever | |
committed | unmodified | A version of the file is in the .git directory |
modified | A modified file that has not been staged (not added to staging area) | |
staged | A modified file that - has been staged (added to staging area) - is ready to be committed. | |
Git status format
| Symbol | Status | Note |
|---|---|---|
| ’ ’ | unmodified | |
| M | modified | |
| T | file type changed (regular file,symbolic link or submodule) | |
| A | added | |
| D | deleted | |
| R | renamed | |
| C | copied (if config option status.renames is set to “copies”) | |
| U | updated but unmerged |
See, https://git-scm.com/docs/git-status#_short_format
note
Staged files will be:
- In a different list (Changes to be committed)
- With the status of
modifed
The other list - Changes not staged for commit - show all unstaged files.
The lifecycle of the status of a file in working tree of a Git repo
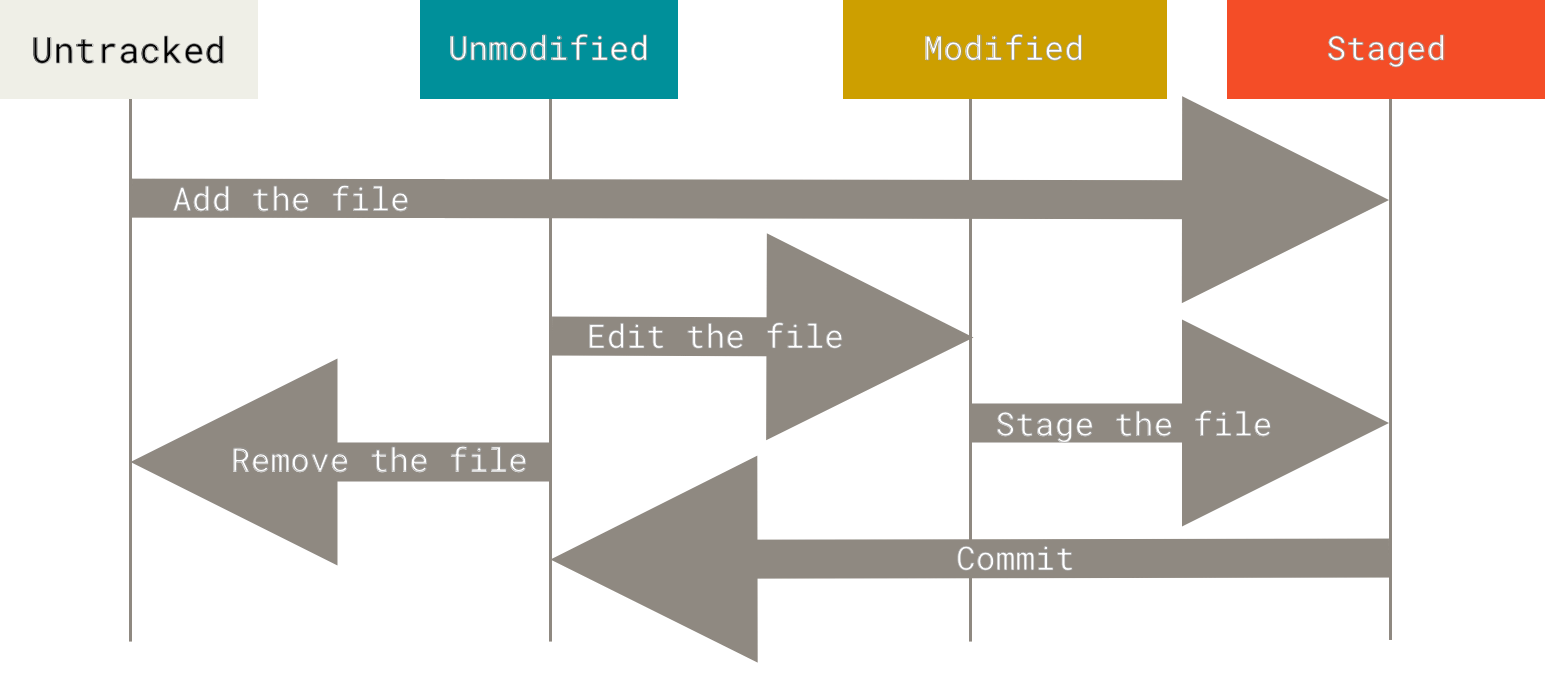
3 main sections of a git Project
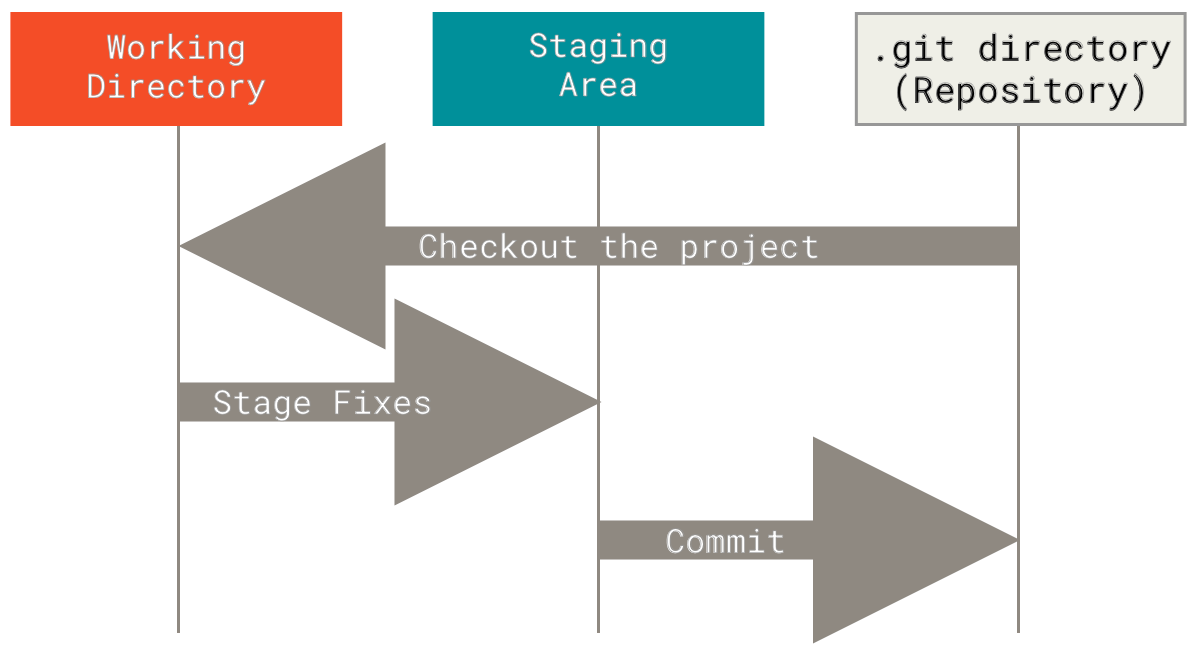
How Git stores data?
[!NOTE] How other VCSs stores data? Most of other VCSs store data as changes to a base version of each file:
- A set of base version of each file
- The changes made to each file (delta) -> File-based changes, delta-based version control.
Git stores data as snapshots of the project overtime.
-
Every time you commit (save the state - ~ a version - of the project), Git:
- takes a snapshot of what all files look like at that moment
- if a file has not changed, Git doesn’t store the file again, it just links to the previous identical file.
- stores a reference to that snapshot
- takes a snapshot of what all files look like at that moment
important
Git is like a mini file-system.
[!NOTE] How Git knows the diff? Git doesn’t know the diff between different versions of a file.
- The diff is generated when needed.
- There are a lot of algorithm to generate the diff - diff algorithms
- Builtin:
default,minimal,histogram,patience,myers- External: Algorithms from
delta,diff-so-fancy…
| Diff algorithm | Description |
|---|---|
| default | basic greedy diff algorithm |
| histogram | generate diffs with histogram algorithm |
| minimal | spend extra time to make sure the smallest possible diff is produced |
| myers | basic greedy diff algorithm |
| patience | generate diffs with patience algorithm |
Branching and Merging
important
Git’s branching model is its killer feature:
- It’s lightweight:
- Operation on branch is nearly instantaneous
- Switching between branches is just as fast
What is a commit?
Remember,
- Git doesn’t store data as a series of changesets, but instead as a series of snapshots.
- Git has integrity: - Everything is checksummed before it’s stored - Everything is then referred to by that checksum When you make a commit, Git:
- (stores the content as a snapshot)
- stores the commit as a commit object that contains
- a pointer to the snapshot of the content
- author’s name & email
- commit’s message
- pointers to its parent commits
[!NOTE] How Git stores a snapshot of your project?
- Each files is checksummed and stored in the bare repository (
.git) as a blob object- A tree object is created to
- lists the content of the directories.
- map the files with the blobs.
- A commit object is created to store
- pointer to the tree object
- commit metadata e.g. author, committer, commit message, size
- pointer to parents
note
The commit or commits that came before another commit is its parent(s).
- The initial commit: zero parents
- A normal commit: one parent
- A merge commit: 2 or 3 parents
What is a branch?
In Git, a branch is simply a lightweight movable pointer to a commit (the last commit or any of its parent).
- Default branch names is
master(now, it can be config tomain) - Every time you commit, the
mainbranch pointer moves forward automatically
note
The main branch is
- not a special branch
- exactly like any other branch
The only reason nearly every repository has one branch name:
master:git initcommand creates it by defaultmain: Github/Gitlab create it by default
| What to do? | How to do? | Example |
|---|---|---|
| Create a branch (based on the current commit) | git branch BRANCH_NAME | git branch testing |
| Create a branch base on a commit | git branch BRANCH_NAME COMMIT_HASH |
[!NOTE] Git branches and
HEADTo know which branch you’re currently on, Git usesHEAD- a special pointer - to point to the local branch you’re currently on.
tip
The git branch command only created a new branch:
- It didn’t switch to that branch, e.g.
testing - You’re still on the previous branch, e.g.
master
[!NOTE] How to change to another branch?
- Use
git checkout BRANCH_NAME- Use
git switch BRANCH_NAME
[!WARNING] Be careful when using
git checkoutto switch branch Thegit checkoutcan
- checkout a branch (updates the working tree to match the branch commit)
- checkout files of a branch (update these files in the working tree to match that branch commit)
Patterns when using Git
Gitflow Pattern
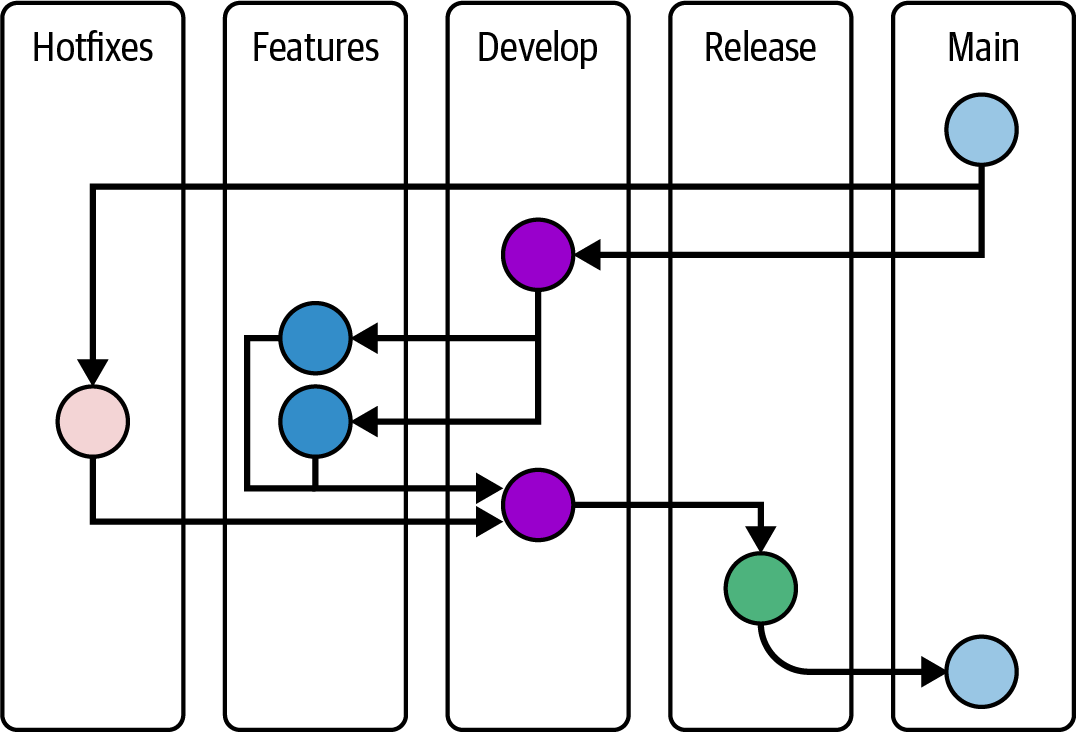
There are several branchs:
- When a
feature/hotfixbranch is finished, it is merge todevelopbranch (the code has been developed) - The
developbranch then merge toreleasebranch to indicate these code is ready to be deployed There may be- a final test round.
- long testing phase with release candidate
During the merging process between branches, there can be one or more layers of approval prior to the merge being allowed.
- These gatekeeping processes ensure quality of code.
- But they also introduce a lot of friction between the development and the production.
Trunk-Based Pattern
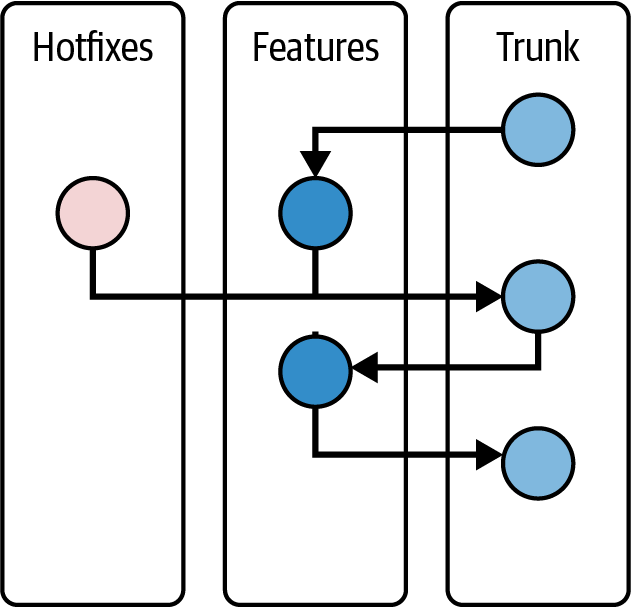
The main idea of trunk-based pattern is to avoid:
- long-running branches
- large merges
by deploying code to production (
trunk) with minimal manually checks and a lot of automating test.
Testing Code
Most of the time, the requirements only include functional one. The non-functional requirements, e.g.
- security
- speed may be in the SLA - service-level agreement.
Unit Testing
unit testing : test in small unit - e.g. function level, small pieces of code : ~ without external dependencies
The main goal of uniting testing:
- ensure the unit work as expected
- maintain code standard
- 100% code coverage
Ideally, all unit tests should be executed in an automated manner.
Integration Testing
integration test : test together units of code : ensure they works together
System Testing
system test : combine all components in an environment as close as possible to the production environment : test both functional & non-functional requirements
Automating Tests
Automation is a key factor in determining the success of a DevSecOps team. There are a lot of tools that help automating testing of code, e.g. Selenium, Python binding to Selenium…
Retrieving a page using Selenium, Python and Firefox
You can run Python code to execute Selenium test that use a headless browser (e.g. Firefox) to:
- capture the screenshot of a site
- crawl a site e.g. Basic Python code to retrieve a web page and capture the result as a screenshot and as a page source
#!/usr/bin/env python
from selenium import webdriver
proto_scheme = "https://"
url = "www.braingia.org"
opts = webdriver.FirefoxOptions()
opts.add_argument('--headless')
driver = webdriver.Firefox(options=opts)
driver.implicitly_wait(10)
driver.get(proto_scheme + url)
driver.get_screenshot_as_file('screenshot.png')
result_file = 'page-source_' + url
with open(result_file,'w') as f:
f.write(driver.page_source)
f.close()
driver.close()
driver.quit()
- Execute the Python code
python3 program.py
# or
# ./program.py
Retrieving text with Selenium and Python
copyright = driver.find_element("xpath", "//p[contains(text(),'Copyright')]")
print(copyright.text)
Summary
- When developing, try to
- be intentional & deliberate
- know why using a pattern, a line of code
- Git and git patterns: gitflow, trunk-based
- Three levels of testing and automation test.
Chap 5. Moving Toward Deployment
Managing Configuration as Code and Software Bill of Materials (SBOM)
Managing Configuration as Code
configuration : files that configure the behavior of services in a modern infrastructure : e.g. Conguration for web server (nginx, Apache)
as code : managed by a VCS like Git (just like code) : Changes can be tracked, rolled back if needed
How to structure configuration?
It’s depend on the OS and infrastructure:
- Per-application
- Per-environment
Structure the configuration per application (with environments)
Use branching & tagging for changes to the files.
Structure the configuration per environment (with applications)
This can lead to a drift between environments, remember to keep the environments as close as possible to the production:
- Any permanent changes to dev, qa… need to be propagated to the production.
- Any temporary changes to dev, qa… needs to be removed before it propagated to production.
note
Structure the configuration per environment leads to variable-based configuration management:
- the configuration files are stored in the source code repository
- instead of hard-coding values, any environment-specific information is gathered at deploy time. (requires additional levels of automation)
Configuration files and SBOM - Software bill of materials
SBOM : information about each components of a software : e.g. name of supplier/component, version, dependencies : used to verify & validate each pieces of a large application
The configuration files is a part of the SBOM:
- They’re the packages need to be installed to make an application work
Using Docker
Docker provides containerization for applications. Containerization : one of the primary tool that enable DevSecOps. : requires a paradigm shift away from monolithic (one giant application) to microservices (micro application that do only one thing)
Container and Image Concepts
container : isolated process - abstraction of hardware resources - provides a computing environment (~ runtime for your application) : lighter than a VM : not a lightweight VM (~ a container is a OS-level virtualization, a VM is a hardware-level virtualization)
container image : a standardized package that includes all of the files, binaries, libraries, and configurations to run a container
note
Form a security perspective, a container image is more secure than a VM image:
- For VM: No one can know exact what’s inside, what’s changed with a VM image.
- For container:
- A container image are composed of layers. And each of these layers, once created, are immutable.
- Each layer in an image contains a set of filesystem changes - additions, deletions, or modifications.
- if one of the base layers for Docker images was tampered with, the community would be made aware immediately.
note
From a operational perspective, a container can use the minimum resource to:
- provide the runtime environment (software)
- make that runtime environment isolated (hardware & software)
With container, you can quickly spin up an instance of your application:
- have a vertical scaling (& also gain performance with the same hardware)
- automate the process of horizontal scaling (with minimal overhead)
- have the container run and exit immediately (serverless)
See:
- https://docs.docker.com/guides/docker-concepts/the-basics/what-is-a-container/
- https://docs.docker.com/guides/docker-concepts/the-basics/what-is-an-image/
Obtaining Images
To run a container, first you need the container image, which:
- you build yourself from the Dockerfile
- someone’s built it, and you only need to pull that pre-built image from a registry, e.g. Docker Hub.
Docker Hub
Docker Hub : the official registry for container images
The Docker Hub can be accessed via:
- its Web UI: https://hub.docker.com/
- Docker Desktop
- via the CLI (its the default registry of the docker CLI)
Using the Docker command
docker search IMAGEdocker pull IMAGEdocker run --name CONTAINER IMAGEdocker psdocker exec -it CONTAINER COMMANDdocker stop CONTAINERdocker start CONTAINER- …
Using a local network registry
If your organization needs full control of the registry, you can
- maintain your own registry
The community maintains an implementation of a container registry:
- The project (
distribution) is at https://github.com/distribution/distribution - The releases are available as container image (
registry) at https://hub.docker.com/_/registry
- The project (
- use SSL (self-signed or CA-signed) to encrypt data on transit
- use
htpasswdto add authentication From the perspective of a developer, he/she will need: - Trust the certificate
- Login to the local registry:
docker login registry.example.com - Sync image from Docker Hub to your local registry
- Pull the image:
docker pull alpine - Retag it:
docker tag alpine registry.example.com/alpine - Push to local registry:
docker push registry.example.com/alpine
- Pull the image:
- Pull from local registry
- (Remove cache images)
docker rmi alpine registry.example.com/alpine - Pull: ``docker pull registry.example.com/alpine`
- (Remove cache images)
Deploying Safely with Blue-Green Deployment
blue-green deployment : deployment strategy that deploys in safe manner by using 2 sets of environment : - blue - the current-production environment : - green - the to-be-production environment : traffic is switched to green after it has been tested
Summary
- Treat configuration as code and manage it using a VCS like Git.
- Containerizing applications to facilitate CI/CD deployment pipeline.
- Blue-green deployment
Chap 6. Deploy, Operate, and Monitor
By the time an application reaches the production environment:
- The code should have been reviewed, tested many times
- The deployment to an environment (qa, uat, …) should have been done many times
- There should be little room for surprises. -> This is also known as shift-left
Continuous Integration and Continuous Deployment (CI/CD)
note
This chapter demonstrate the use of
- Ansible (for maintaining environments)
- Jenkins (for deployment)
Many organizations may outgrow this deployment mode, e.g.
- Use other tools:
- Terraform
- Kubernetes, ArgoCD
- Deploy on multiple clouds with other cloud-native tools
Building and Maintaining Environments with Ansible
note
Ansible - just like Chef, Puppet - is configuration management tools:
- can operate without agent (agent-less)
- use declarative approach (configuration is managed as code in YAML/INI format)
Ansible concepts
inventory : defines the hosts being managed : : ~ which servers
e.g. A group of servers (that mean to be DNS servers)
playbook : defines the automation tasks to get the desired state of the hosts : ~ what to do (to which servers)
e.g. What to do to make these server up-and-running as a DNS server
- Install DNS-related software, e.g. BIND
- name: ensure installed- bind9
apt: name=bind9 state=present
- Sync the configuration to the device under managed
- name: sync named.conf
copy: src={{ config_dir }}/dns/named.conf dest=/etc/bind/named.conf group=bind backup=yes
notify:
- restart named
tags:
- bindconfigs
How Ansible works?
With Ansible, you can
- create a desired state for environments
- execute automation tasks to configure these environment
with a single command
ansible-playbookby using a configuration as code approach.
Using Jenkins for CI/CD
Jenkins : an automation server - support automating virtually anything, so that humans can spend their time doing things machines cannot. : powerful & extensive : ~ CI/CD server
Why Jenkins?
Automate your development workflow:
- building projects
- running tests
- static code analysis
- deployment
- … so you can focus on work that matters most.
Setup a Jenkins server
Creating a simple Pipeline with Jenkins
A simple pipeline that deploy a application to a server looks like this:
- Pull code
- Build code
- (Test code)
- (Release code)
- Deploy code
Connect to a server
ssh
| Server | Client | |
|---|---|---|
| SSH key-pair | Public key | Private key |
| ssh/ | ||
| Authentication data | ~/.ssh/authorized_keysThe users that are allowed to log in remotely | ~/.ssh/known_hostsPublic keys of the hosts accessed by a user |
| (Is this the user that I should let log in?) | (Is this the same server I’ve connected last time?) |
Public-key cryptography
Public-key cryptography (asymmetric cryptography) : The field of cryptographic systems that use pairs of related keys. : Each key-pair consists of a public key and a corresponding private key : Security of public-key cryptography depends on keeping the private key secret; the public key can be openly distributed without compromising security
In a public-key encryption system,
- anyone with a public key can encrypt a message, yielding a ciphertext,
- but only those who know the corresponding private key can decrypt the ciphertext to obtain the original message.
In a digital signature system,
- a sender can use a private key together with a message to create a signature.
- anyone with the corresponding public key can verify whether the signature matches the message, but a forger who does not know the private key cannot find any message/signature pair that will pass verification with the public key
ssh
| SSH | ELI5 | |
|---|---|---|
| Why | Remote login, command-line execution… | A server is crashed, you need to login to your server and fix it |
| What | Network protocol for provide secure encrypted communications between two un | You can send your backend code to your server over the public wifi |
| How | SSH uses public-key cryptography and challenge-response authentication | You can only login to your server if you have your private key |
ssh
: SSH - the protocol
: ssh - the program
ssh (the program)
: OpenSSH remote login client
: a program for
: - logging into a remote machine
: - executing commands on a remote machine
OpenSSH
| OpenSSH tool | Docs - What is it? | tldr - What it does? | |
|---|---|---|---|
| Server | ssh-agent | OpenSSH authentication agent | Holds SSH keys decrypted in memory |
sshd | OpenSSH daemon | Allows remote machines to securely log in to the current machine | |
| Key management | ssh-add | Adds private key identities to the OpenSSH authentication agent | Manage loaded SSH keys in the ssh-agent |
ssh-keygen: | OpenSSH authentication key utility | Generate SSH keys used for authentication | |
ssh-keyscan | Gather SSH public keys from servers | Get the public SSH keys of remote hosts | |
| Client | ssh | OpenSSH remote login client | Logging or executing commands on a remote server |
note
The ssh-copy-id is used when:
- you have logged in to a remote server (by using a login password),
- you need to copy SSH public keys to that remote server’s
authorized_keys.
A normal flow when working with OpenSSH
warning
Any one have your private key can do malicious things in your name.
| When? | What? | How | Where? | Note |
|---|---|---|---|---|
| 1. | An SSH key-pair is generated | e.g. Use ssh-keygen | Anywhere | |
| 2. | The key-pair is distributed | |||
| 2.a. | - to the server: public key | In file ~/.ssh/authorized_keys on the s | ||
| 2.b. | - to the client: private key | In directory ~/.ssh/ on the client | ||
| 3. | Login to the server | Use ssh | On the client | - The first time you connect to a server, you need to confirm the server by the fingerprint of the public key. - After you confirmed, the server’s public key is saved to the client’s known_hosts |
Key-pair, public/private key, passphrase, fingerprint, randomart image
-
Private key: is known only to you and it should be safely guarded
-----BEGIN OPENSSH PRIVATE KEY----- b3BlbnNzaC1rZXktdjEAAAAABG5vbmUAAAAEbm9uZQAAAAAAAAABAAAAMwAAAAtzc2gtZW QyNTUxOQAAACCLdbmJdwnuwFEb4syAWfwkFrkVEbTOM28u9TDlA5D5qgAAAJDy28+G8tvP hgAAAAtzc2gtZWQyNTUxOQAAACCLdbmJdwnuwFEb4syAWfwkFrkVEbTOM28u9TDlA5D5qg AAAEC78OkniXvREV3umKoZY3r+jYPXXAyocmGV0gFf+xmKZYt1uYl3Ce7AURvizIBZ/CQW uRURtM4zby71MOUDkPmqAAAAC2xxdEBsZy1ncmFtAQI= -----END OPENSSH PRIVATE KEY----- -
Public key: can be shared freely with any SSH server to which you wish to connect.
ssh-ed25519 AAAAC3NzaC1lZDI1NTE5AAAAIIt1uYl3Ce7AURvizIBZ/CQWuRURtM4zby71MOUDkPmq username@hostname -
Passphrase: an extra protection layer for the private key, used to encrypt/decrypt the private key on the client
-
Fingerprint (Public key fingerprint): a short hash of the public key, provides an easy way to visually identifying the key
e.g.
-
SHA256
SHA256:qkb5wD2QW8+ASMWiGnSEEE/heGuugC9gH20yFpq/jn0 username@hostname -
MD5
MD5:73:ee:67:ef:53:2b:84:d7:4e:bc:5c:14:78:90:a5:53 username@hostname
-
-
Randomart image: an even easier way for humans to identify the key (fingerprint)
e.g.
+--[ED25519 256]--+ |+.==. | | Bo.. | |oo=o o | |o..o+ o | |..=.o* +S | |+* =*oo.o | |= =.=o.. | |oooo.E. | |.oo=+ | +----[SHA256]-----+
SSH Key format and key type
The following SSH key formats are supported by OpenSSH:
| SSH key format | Note | aka |
|---|---|---|
PEM | Used by GitHub | OpenSSL’s format |
PKCS8 | ||
RFC47161 | Default when exporting | SSH2 |
| OpenSSH’s format | Default when creating |
The following SSH key type are supported by OpenSSH:
| SSH key type | Note | Pros / Cons | Example |
|---|---|---|---|
rsa | Greatest portability | ssh-keygen -b 4096 | |
dsa | (Deprecated) | ||
ecdsa | (Prefer ed25519) | Political/technical concerns | |
ed25519 | (Default) | Best security | ssh-keygen -t ed25519, ssh-keygen |
tip
There are also ecdsa-sk, ed25519-sk:
- These key type are created with FIDO/U2F hardware token, e.g. YubiKey
-skstands for security key
Transfer files between servers
Clone source code to Jenkins server
git
To the production server
rsyncscp
Monitoring
The complexity to deploy a modern application has increased significantly:
- Many organizations even requires no downtime between deployments.
To keep the complexity under control, you need to monitor it to know
- what happening with the application
- how it’s running
Best practices for monitoring
-
Visibility means fix-ability:
e.g. Knowing about an outrage before someone call you can give you some time.
-
Triage is important
e.g. Which problem should you spend your time?
-
Shift downtime left with instrumentation enabled
e.g. Downtime in non-production environments is also needed to be fixed early
-
Focus on important metrics
e.g.
- I/O latency for a database is important metric
- Requests/second, request latency is important metrics for a web server
-
Don’t forget dependencies
e.g. Network latency is uncontrolled.
-
Alerts need to be actionable
e.g. No one care if a job they don’t care about success.
If a job is not actionable, it should be a log not an alert.
Summary
- Ansible: provision infrastructure
- Jenkins: create CI/CD pipelines
- Monitoring & best practices
(https://www.ietf.org/rfc/rfc4716.txt)
Chap 7. Plan and Expand
Scaling Up with Kubernetes
- Docker: VM -> Container
- Docker Compose: Multi containers
- K8s: A lot of containers (thousands) -> Container orchestration
Understanding Basic Kubernetes Terms
Kubernetes’s architecture:
- Control plane(s):
- A key/value store -
etcd - An API server -
kube-apiserver - A controller manager -
kube-controller- responsible for node/job management… - A scheduler -
kube-scheduler- responsible for containers management
- A key/value store -
- Worker node(s):
- An agent -
kubelet - A proxy -
kube-proxy: responsible for network communication - A container runtime, e.g.
containerd: The original one by Dockercri-o: Open Container Initiative-based implementation of Container Runtime Interface for Kubernetescri-dockerd: dockerd as a compliant Container Runtime Interface for Kubernetes
- An agent -
Kubernetes concepts
cluster : the components that constitutes an entire Kubernetes installation
pod : a group of containers
service : ~ a network-based listening service
Create a Kubernetes cluster
- Setup your own K8s cluster with
kubeadm1- Install
kubeadm - Create a cluster’s control plane with
kubeadm init
- Install
Add networking
Add networking with Calico
Add nodes to Kubernetes cluster
Join other nodes to your Kubernetes cluster with kubeadm join
- as worker nodes
- or as control planes
For more way to setup a Kubernetes cluster, see Installing Kubernetes with deployment tools
Re-creating the join command
When interact with the cluster, you need to provide the token for authentication.
These token is available:
- when use initialize the cluster
- via the
kubeadm tokensub-commands:list,create…
Remove nodes from Kubernetes cluster
Before a node can be removed, it needs to be drained so no more workload run on it.
# On the control plane
kubectl drain <node>
kubectl delete <node>
# On the node, "reset" to cleanup the node
kubeadm reset
Deploying with Kubernetes
With Kubernetes, you can
- treat multiple containers as a single deployed unit - called pod - (the same as Docker Compose)
- have redundancy of your pods via replicas
For Kubernetes, a configuration is in form of a file in YAML language, which can be treat as code.
Defining a Deployment
Deployment : enables declarative updates of Pods (and ReplicaSets) : ~ you declare the end state (of a pod), K8s ensure the pod has that end state
Using a ConfigMap
ConfigMap : holds configuration data for pods to consume
note
Isn’t the while yaml file is a configuration data store in the configuration file, now there is configuration data. 🤔
e.g.
# configmap1.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: configmap-chapter7-1
# <Data> contains the configuration data
data:
# Block scalar (2 styles: | or >): | Keep newlines (one newline at end)
index.html: |
<!doctype html>
<html>
<head>
<title>Deployment 1</title>
</head>
<body>
<h1>Served from Deployment 1</h1>
</body>
</html>
Creating the Deployment file
# deploy1.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment-chapter7-1
spec: # <DeploymentSpec> spec - "specification"
replicas: 2 # Number of replicas
selector: # K8s uses the selector to unify other K8s resources into this deployment
matchLabels:
app: nginx
template: # <PodTemplateSpec>
metadata:
labels:
app: nginx # This label will be used later
spec: # <PodSpec>
containers: # <>
- name: nginx
image: nginx
ports:
- containerPort: 80
volumeMounts:
- name: config-chapter7-1
mountPath: /usr/share/nginx/html
volumes:
- name: config-chapter7-1
configMap:
name: configmap-chapter7-1 # Match the metadata field of configmap1.yaml
Running the Deployment
# Apply the configuration to ConfigMap resource (If the resource doesn't exist yet, K8s will create it)
kubectl apply -f configmap1.yaml
# Apply the configuration to Deployment resource
kubectl apply -f deploy1.yaml
Verifying the Deployment
-
Get one/more resources
-
In ps format (default)
kubectl get configmaps kubectl get deployments kubectl get pods kubectl get all -
In ps format with more information
kubectl get pods -o wide -
In yaml/json format
kubectl get pods -o yaml
-
-
Get one/more resources in detail
# Detail about ... all pods kubectl describe pods # ... all configmaps (all object of ConfigMap type) kubectl describe configmaps # ... a configmap named kube-root-ca.crt... kubectl describe configmaps/kube-root-ca.crt # ... any configmap with name prefix kubectl describe configmaps kube # ... any configmap with a select (label query) kubectl describe configmaps --selector project=awesome-project
Defining a Service
Service
: a named abstraction of software service (for example, mysql), consisting of
: - local port (e.g. 3306) that the proxy listens on,
: - the selector that determines which pods will answer requests sent through the proxy.
: ~ K8s abstracts away your application, it is exposed only via the K8s Service to be available outside of the cluster to the world
e.g.
-
The Service’s configuration:
# service.yaml apiVersion: v1 kind: Service metadata: name: service-chapter7 spec: selector: app: nginx # This is the label of the pods to be selected, match with the the deployment template's label type: NodePort ports: - name: http port: 80 targetPort: 80 nodePort: 30515 externalIPs: - 192.168.1.158 # Set to the IP of the K8s controller, depends on the service type, it can be auto-assigned -
Create the service
kubectl apply -f service.yaml -
Test the service
curl http://192.168.1.158
Moving Toward Microservices
Apply another set of configmap, deployment, service for another application, and you’ve a microservices system deploy a K8s cluster.
Connecting the Resources
To organize the configuration files of an application, you can
- put all 3 configuration file of configmap, deployment, and service into a single configuration file, e.g.
app-a.yaml - or keep using multiple files with a name standard to distinguish between applications.
Integrating Helm
tip
How to install a software in the old days?
- Download a tar archive, e.g. gzipped
- Unarchive
- Build the app:
make && make install - If something went wrong,
rm -rf config.cache && make clean
Today, the industry use package manager to install software (& its dependencies), e.g.
- Linux:
apt/dpkgon Debian/Ubuntu,yum/dnfon Fedora/RHEL - Mac:
Homebrew - Windows:
winget,chocolatey - Docker’s container images are also managed as packages
- Kubernetes: it’s Helm
Helm concepts
Helm chart : a packages of pre-configured Kubernetes resources : describe the desired state of an application, including all of the prerequisites needed to run it : stored in chart repositories
Helm : a tool for managing Charts : ~ install, manage Kubernetes applications
Helm repository
: a location where packaged charts can be stored and shared.
: ~ a HTTP server that serves index.yaml & packaged charts.
: Beginning in Helm 3, you can use container registries with OCI support as a Helm repository
: e.g.
: - a community Helm chart repository located at Artifact Hub
: - self-maintain repo: bitnami
release : an installation of a chart become a release : with Helm, you can install the same chart multiple times, and have multiple releases (of the same chart)
warning
Most of other package managers only allow one installation of a package.
Helm acts both as a package manager (e.g. npm) & a version manager (e.g. nvm).
Discovering Helm charts
You can search for charts:
-
In community Helm repository at Artifact Hub
helm search hub <mysql> -
In repo that’s you added
helm search repo <mysql>
Or you can use the Artifcat Hub web interface which has more information (including popularity).
Summary
- Kubernetes:
- What?
- Docker: VM -> Container
- Docker Compose: Multi containers
- K8s: A lot of containers -> Container orchestration
- Why?
- Auto deploy/scaling/manage containerized applications
- Abstract several application layers
- What?
- Kubernetes - How?
- Deploy application
- Troubleshoot
- Integrate Helm with Kubernetes
https://kubernetes.io/docs/setup/production-environment/tools/kubeadm/create-cluster-kubeadm/
Chap 8. DevSecOps Patterns & Beyond
-
What exactly is DevSecOps?
It means different things to different people depends on context, experiences, organization need.
-
DevSecOps is not a mature enough to have a recipe for success.
-
DevSecOps is not an
end goal, but rather an iterative improvement process to make software delivery faster & more reliable.
DevSecOps Patterns
Shifting Left toward CI/CD
CI/CD is the ultimate gold of Dev(Sec)Ops.
-
A developer should be able to
- write code
- see the code moving to production
- passe tests… (CI)
- deploy to production (CD)
-
ArgoCD is designed with DevSecOps in mind:
- There is a web interface to increase visibility: developers can see what see deployment status of the system.
- Takes advantages of tools: K8s, Helm…
Multi-cloud Deployments
With
- containerization technology: Docker, Kubernetes
- the support of cloud providers to provide a platform for containers that integrates well Kubernetes
any organization can run containerized workflow seamlessly on any cloud provides based on:
- organization need
- geographic demand
- redundancy
Integrated and Automatic Security
The whole SDLC should be secure by default, in an unobtrusive way:
-
Role-based access control should be everywhere.
-
In addition to post-production, security needs to be shifted left and automatic (developers don’t need to be an expert in cybersecurity):
-
When code is committed/pushed, the CI system’s security scanning tool should flag the security issues so developers can remediation these security issues early.
e.g. Credentials, secrets within code/configuration needs to be remove ASAP.
-
The tooling should minimize the any security risks for the developers.
-
Linux Everywhere
Promoting tools that:
- are Linux-based
- work seamlessly with Linux
Linux-related skills - utilizing CLI, understand Linux’s architecture … - should be promoted in an organization.
Refactor and Redeploy
For a bare-metal/VM server,
- the cost of deploying another instance is quite high (the hardware purchasing, the setup…)
- the cost of getting the most from the existing instances is cheaper, optimization & troubleshooting skills is more emphasized.
Today, the time spending to get the most out of an instance is more costly than a redeploy:
- Computing resources - processor, memory - are cheap enough that a deployment of another instance is cheaper than determine the root-cause of an instance.
- You can treat redeploying as “turning it off and back on again”
Summary
-
DevSecOps patterns:
- Shift-left (deployment, security)
- Multi-cloud deployment
- Linux (& its skills)
- Redeploy
-
DevSecOps is more than a practice, it’s the culture
- Change the culture first, then introduce the DevSecOps practices, tools.
- Don’t make DevSecOps a technical debt to sole other technical debts.