Chap 4. Managing Code and Testing
As in [[chap-01#The DevSecOps SDLC]], we’ve known that Dev, Built, Test is three steps of the DevOps SDLC
Examining Development
For high-level programming design and architectural, you can look for
- books published by O’Reilly.
- books written by Marin Fowler
[!NOTE] > TCP/IP Illustrated series by W. Richard Stevens are good books for networking.
Be Intentional and Deliberate
Write code that
- is easy to read and maintain.
- doesn’t introduce technical debt.
note
Technical debt implied cost of future reworking required when choosing an easy but limited solution instead of a better approach that could take more time
question
Hard-coding values & magic numbers: What and when? %% TODO: Research this %%
Don’t Repeat Yourself
According to Wikipedia, “Don’t repeat yourself” (DRY) is
- a principle of software development
- aimed at reducing repetition of information which is likely to change,
- replacing it with abstractions that are less likely to change, or
- using data normalization which avoids redundancy in the first place.
In Pragmatic Programmer, DRY principle is “Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.”
If the same value is used in different places,
- Give it a name (don’t hard-coding it).
- Instead of directly using the values, using the name.
caution
If the same value are in different places, ask whether they’re the same purpose, before DRY?
tip
Don’t apply DRY to everywhere and at any times.
- Some developers will try their best to remove duplication in code.
- There is a proverb in Golang, A little copying is better than a little dependency.
- There are also WET, AHA…
Managing Source Code with Git
note
There are a lot of Versicion Control System (VSC): CSV, SVN, Mercurial, Git…
See https://en.wikipedia.org/wiki/Version_control#Version_control_software
note
VCS is aka is Source Code Management (SCM) system
Git is the most popular SCM for now (with the raising of open-source software and GitHub)
Git - a distributed version control system (DVCS)
Git is a distributed VCS:
- clients don’t just check out the latest snapshot of the files; rather, they fully mirror the repository, including its full history.
- every clone is really a full backup of all the data.
The distributed nature of Git allow a vast ranges of workflow for your project and your team:
- Centralize workflow: one repository can accept code, everyone synchronizes their work with it e.g. Most closed source software use this workflow
- Integration-Manager workflow:
- each developer (contributor)
- has write access to their own public repository & read access to everyone else’s.
- send a request to the maintainer of the main repository
- the maintainer - adds the contributor’s repository as a remote & merge locally - pushed merged changes to the main repository e.g. GitHub’s fork (feature) & open-source software
- each developer (contributor)
- Dictator and Lieutenant workflow:
- contributor
- works on their topic branch
- rebase on top of
master
lieutenant: merges contributor’s topic branch into lieutenant’s master branchdictator: - merges lieutenant’s master branch into dictator’s master branch - push dictator’s master branch to master remote repository e.g. Big project: Linux
- contributor
Git on the server
To collaborate in Git, you’ll need a remote Git repository, which everyone can
- have access to
- push to, pull from
warning
Technically, you can push/pull changes directly to a repository on another Git client.
But don’t do it! It will be a nightmare!
Git remote repository
A remote repository is generally a bare repository - a Git repository that has no working directory.
note
You can get a bare repository with:
git initgit clone --bare
After run these two commands, you’ll get a repository with only the .git directory.
Git’s transfer protocols
Git supports 4 protocols to transfer data (to a remote repository)
- Local protocol
- HTTP/s
- Secure Shell (SSH)
- Git
Local protocol
Git use Local protocol when the remote repository is
- in another directory on the same host
- in a shared file system
e.g.
- Clone a local repository
$ git clone /srv/git/project.git- withoutfile://- Git uses hardlinks or directly copy the files it needs$ git clone file:///srv/git/project.git- withfile://
warning
When you specifies file://, Git fires up the processes that it normally uses to transfer data over the network, which is less efficient
Use file:// when import from another VCS
- Add a local repository to an existing Git project
$ git remote add local_proj /srv/git/project.git
HTTP/s
Git can communicate over HTTP using 2 modes:
- Dump HTTP - prior to Git 1.6.6
- Smart HTTP - from Git 1.6.6
Dumb HTTP
Dumb HTTP serves the bare Git repository like normal files from the web server.
- You
- put the bare Git repo under the HTTP document root
- set up a post-update hook
- Anyone can access the webserver can also clone the repo.
Smart HTTP
Smart HTTP
- works similarly to SSH but can run over standard HTTPS port
- can use various HTTP authentication mechanisms e.g. username/password: easier for the user than SSH keys
- can setup to both:
- serve anonymously like
git://protocol - push over with authentication, encryption when needed e.g. An anonymous user can read the repo, if they need to write to the repo, it will require authentication.
- serve anonymously like
note
With Smart HTTP, the user can:
- use a single URL for all type of access
- use username/password (without having to generate SSH keys locally, then update public key before able to do anything)
- use it anywhere (HTTP/s ports are open anywhere)
warning
- Git over HTTPS can be a little more tricky to setp up compare to SSH
- When using Git over HTTP, by default the user needs to enter password everytime he/she need to interact with Git server:
- This can feels a little frustrated, and more complicated than SSH
- The user can use the OS’s credentials caching tools - e.g. MacOS Keychain, Windows Credential Manager - to solve this problrem
Secure Shell (SSH)
tip
SSH access to servers is
- usually already set up in most places
- if it isn’t, it’s easy to do
For example, to clone a Git repo over SSH
- using
ssh://URL$ git clone ssh://[user@]server/project.git - using shorter scp-like syntax
$ git clone [user@]server:project.git
tip
If user@ is not specified, Git assumes the user you’re currently logged in as.
| Pros | Cons |
|---|---|
| - SSH is easy to setup (on the server) - SSH is secure (data is encrypted & authenticated) - SSH is efficient (data is compressed before transfered) | - SSH doesn’t support - Even a read-access (to the repo) need to have SSH access (to the machine) |
note
SSH Protocol can use HTTPS port (443), which is call SSH over HTTPS, but it’s still SSH.
Git
Git protocol
- is a special daemon that comes with Git
- listens on port
9418- similar to port
22of SSH
- similar to port
- unsecured
- a repo is available publicly (with full access) or is not available
| Pros | Cons |
|---|---|
| - Fastest network transfer protocol | - Unsecured - Attacker can do a man-in-the-middle attack and insert malicious code to the repo - Unauthenticated - Most difficult to set up - Require its own daemon - Require firewall access to port 9418 |
note
The URL for Git protocl is git://
warning
A Github’s repo may have URL begins with git, but in fact it’s SSH protocol.
e.g. git@github.com:facebook/react.git
- The prefix
gitis the user at thegithub.comserver - The suffix
.gitis the convention that indicates a directory is a git bare repository
A Simple Setup for Git
Set up a Git server
We’ll go through the process of setup a Git server with some assumptions:
- The server is at
git.example.comwith a repository namedmy_projectat/src/git - The repositories on the server are stored at
/srv/git- The project is
my_project, whose bare repository is at/src/git/my_project.git
- The project is
- You have SSH access to the server as a user named
user
Get a bare repository of the Git repository
On your local machine, you’ll to get a bare repository of my_project repository:
- Use
git clone --baregit clone --bare my_project my_project.git - Or use
cp(there will be some minor differences in the configuration file)cp -rf my_project/.git my_project.git
Putting the bare repository on a server
Use scp command to copy files between hosts using the Secure Copy Protocol over SSH:
scp -r my_project.git user@git@example.com:/srv/gitShare the remote repository with other peoplegit init --sharedGit with automatically add group write permissions to the repository
note
At this point, other users who have SSH-based access to the srv/git directory on that server with:
- read permission can clone your repository with:
git clone user@git.example.com:/srv/git/my_project.git
- write permission can push to your repository with:
git push
Setup up user management
You can control access to your repository by:
- using SSH access Anyone that have SSH access (read/write) to the server can also access the repository
- using the server OS file-system permission
Using SSH access
When using SSH access as the user management for your Git server, you can:
- Create user accounts for everyone
- And run
adduser, set temporary passwords for every new user.
- And run
- Create a single
gituser account on the Git server- Add SSH public keys of all people that have write access to
~/.ssh/authorized_keys
- Add SSH public keys of all people that have write access to
- Have your SSH server authenticate from an LDAP server or an other centralized authentication source.
How SSH Key works
Public-key cryptography:
- Public-key cryptography, or asymmetric cryptography, is the field of cryptographic systems that use pairs of related keys.
- Each key-pair consists of a public key and a corresponding private key
- In a public-key encryption system,
- anyone with a public key can encrypt a message, yielding a ciphertext
- but only those who know the corresponding private key can decrypt the ciphertext to obtain the original message.
- Security of public-key cryptography depends on keeping the private key secret; the public key can be openly distributed without compromising security. SSH and public-key cryptography:
- SSH uses public-key cryptography to authenticate the remote computer and allow it to authenticate the user, if necessary. e.g. - The SSH server - keeps the public key of any host that want to have access to it. - If a host has the private key corresponding to a public key on the SSH server, that host can access to the SSH sever. Setup authenticate with a SSH key-pair:
- Check if there’s one existed at
~/.ssh - If not, generate one:
- On Linux/Mac, use
ssh-keygen
- On Linux/Mac, use
Using OS file-system permission
Using Git (Briefly)
When using Git to manage source code, the basic workflow looks like
| Step | Command | Description |
|---|---|---|
| Init repo | git init | Initializes a new Git repository |
| Clone repo | git clone | After you clone the repo, you’ll have:
|
| Write code | When you write code, you’re making changes to the working copy | |
| Commit code | git add | Add the changes to the staging area (stage a file for commit) |
git commit | Commit the staged changes (as a snapshot) to the local repository | |
| Push code | git push | Pushes the committed snapshots to the remote repository |
| Merge code | git merge | Merges code when collaborating with other developers |
note
You can use git commit -a to commit all modified and deleted files without adding them to staging area.
Commit code: Record changes to the repository
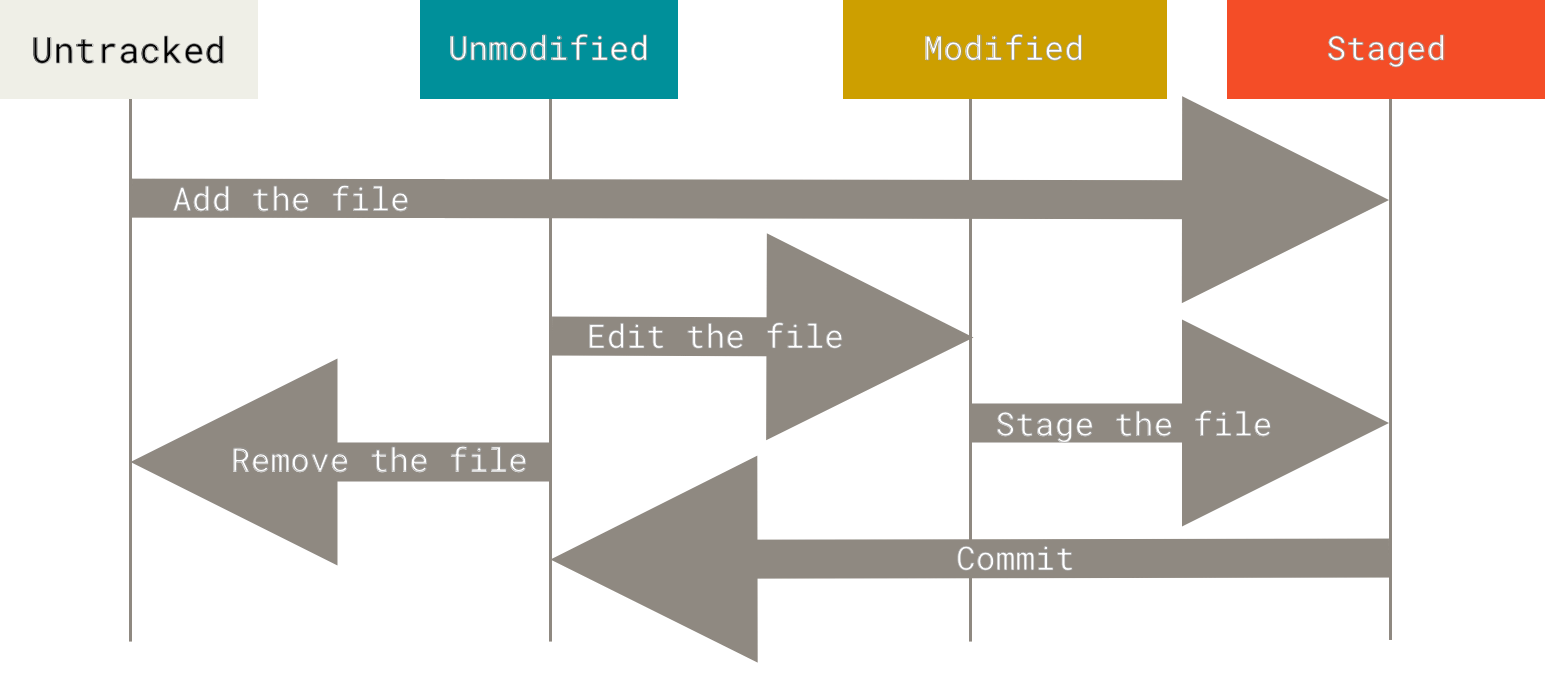
Git knowledge about working tree’s files
Each file the working area can be in one of 2 states:
- untracked: file that Git doesn’t know about
- tracked: file that Git knows about & has the status of :
- unmodified (committed) (tracked file that is not modified)
- modified (tracked file that is modified)
- staged (staged file ready for commit)
- ..
Git concepts
| Term | Alternative names | What is it? What does it mean? |
|---|---|---|
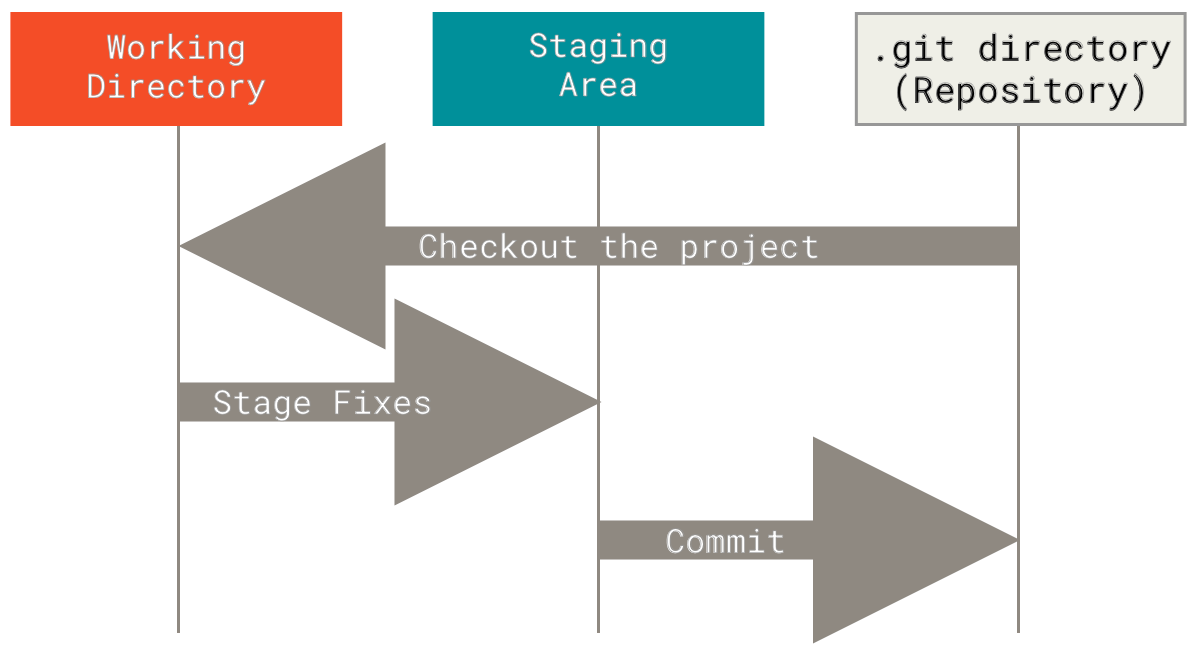
| Working copy | working directory, working tree, workspace | Everything in the repository directory except .git |
| Staging area | index | |
| Local repository | history | |
| Remote repository | sever | |
committed | unmodified | A version of the file is in the .git directory |
modified | A modified file that has not been staged (not added to staging area) | |
staged | A modified file that - has been staged (added to staging area) - is ready to be committed. | |
Git status format
| Symbol | Status | Note |
|---|---|---|
| ’ ’ | unmodified | |
| M | modified | |
| T | file type changed (regular file,symbolic link or submodule) | |
| A | added | |
| D | deleted | |
| R | renamed | |
| C | copied (if config option status.renames is set to “copies”) | |
| U | updated but unmerged |
See, https://git-scm.com/docs/git-status#_short_format
note
Staged files will be:
- In a different list (Changes to be committed)
- With the status of
modifed
The other list - Changes not staged for commit - show all unstaged files.
The lifecycle of the status of a file in working tree of a Git repo
3 main sections of a git Project
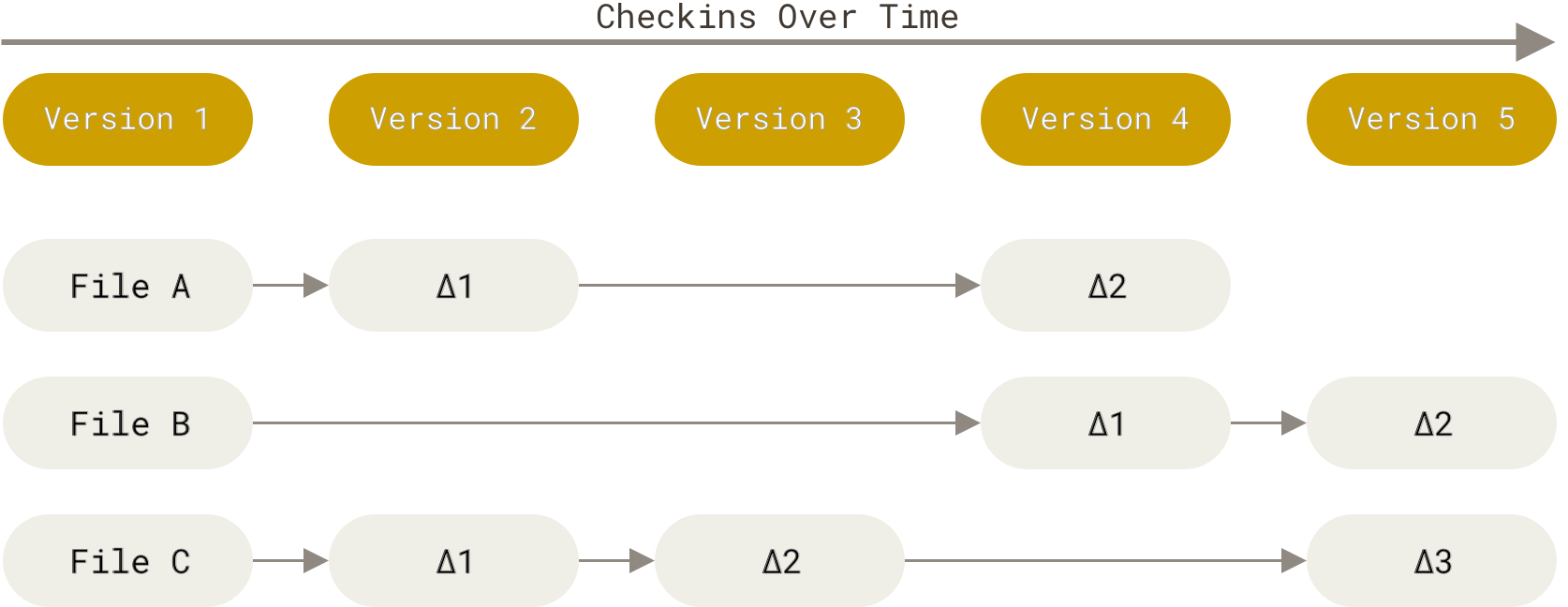
How Git stores data?
[!NOTE] How other VCSs stores data? Most of other VCSs store data as changes to a base version of each file:
- A set of base version of each file
- The changes made to each file (delta) -> File-based changes, delta-based version control.
Git stores data as snapshots of the project overtime.
-
Every time you commit (save the state - ~ a version - of the project), Git:
- takes a snapshot of what all files look like at that moment
- if a file has not changed, Git doesn’t store the file again, it just links to the previous identical file.
- stores a reference to that snapshot
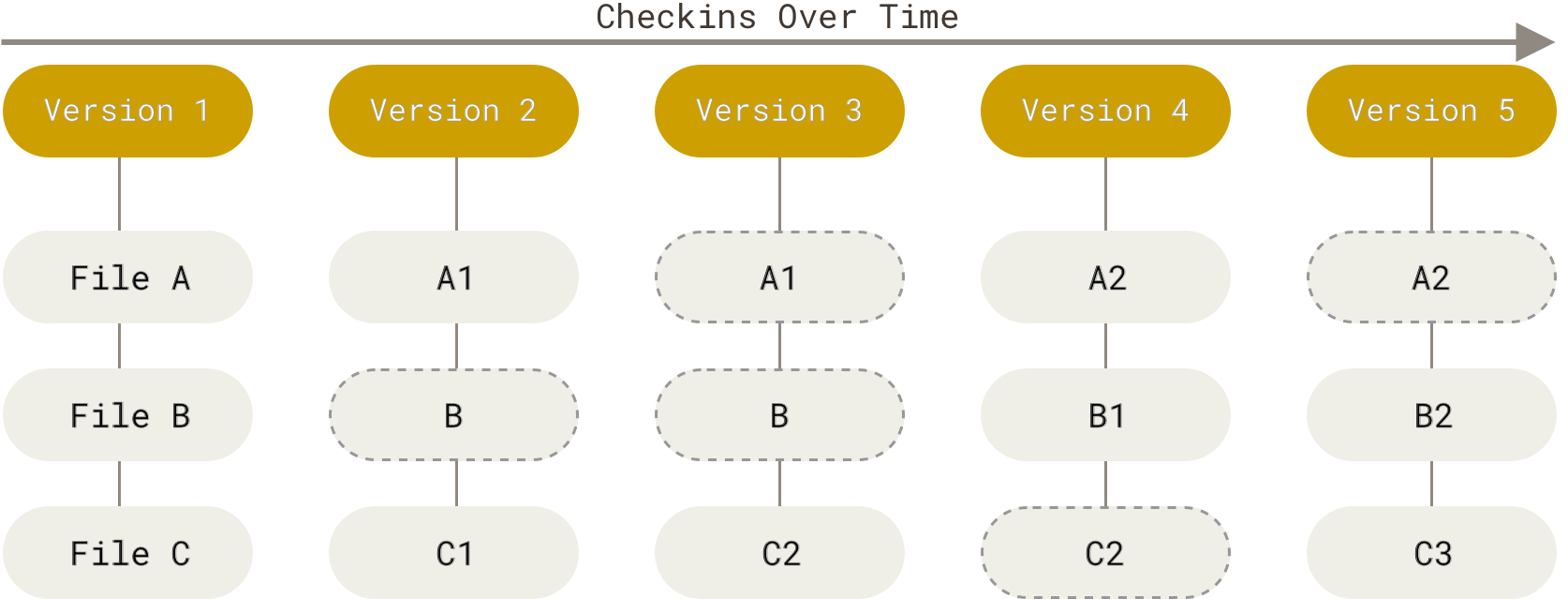
- takes a snapshot of what all files look like at that moment
important
Git is like a mini file-system.
[!NOTE] How Git knows the diff? Git doesn’t know the diff between different versions of a file.
- The diff is generated when needed.
- There are a lot of algorithm to generate the diff - diff algorithms
- Builtin:
default,minimal,histogram,patience,myers- External: Algorithms from
delta,diff-so-fancy…
| Diff algorithm | Description |
|---|---|
| default | basic greedy diff algorithm |
| histogram | generate diffs with histogram algorithm |
| minimal | spend extra time to make sure the smallest possible diff is produced |
| myers | basic greedy diff algorithm |
| patience | generate diffs with patience algorithm |
Branching and Merging
important
Git’s branching model is its killer feature:
- It’s lightweight:
- Operation on branch is nearly instantaneous
- Switching between branches is just as fast
What is a commit?
Remember,
- Git doesn’t store data as a series of changesets, but instead as a series of snapshots.
- Git has integrity: - Everything is checksummed before it’s stored - Everything is then referred to by that checksum When you make a commit, Git:
- (stores the content as a snapshot)
- stores the commit as a commit object that contains
- a pointer to the snapshot of the content
- author’s name & email
- commit’s message
- pointers to its parent commits
[!NOTE] How Git stores a snapshot of your project?
- Each files is checksummed and stored in the bare repository (
.git) as a blob object- A tree object is created to
- lists the content of the directories.
- map the files with the blobs.
- A commit object is created to store
- pointer to the tree object
- commit metadata e.g. author, committer, commit message, size
- pointer to parents
note
The commit or commits that came before another commit is its parent(s).
- The initial commit: zero parents
- A normal commit: one parent
- A merge commit: 2 or 3 parents
What is a branch?
In Git, a branch is simply a lightweight movable pointer to a commit (the last commit or any of its parent).
- Default branch names is
master(now, it can be config tomain) - Every time you commit, the
mainbranch pointer moves forward automatically
note
The main branch is
- not a special branch
- exactly like any other branch
The only reason nearly every repository has one branch name:
master:git initcommand creates it by defaultmain: Github/Gitlab create it by default
| What to do? | How to do? | Example |
|---|---|---|
| Create a branch (based on the current commit) | git branch BRANCH_NAME | git branch testing |
| Create a branch base on a commit | git branch BRANCH_NAME COMMIT_HASH |
[!NOTE] Git branches and
HEADTo know which branch you’re currently on, Git usesHEAD- a special pointer - to point to the local branch you’re currently on.
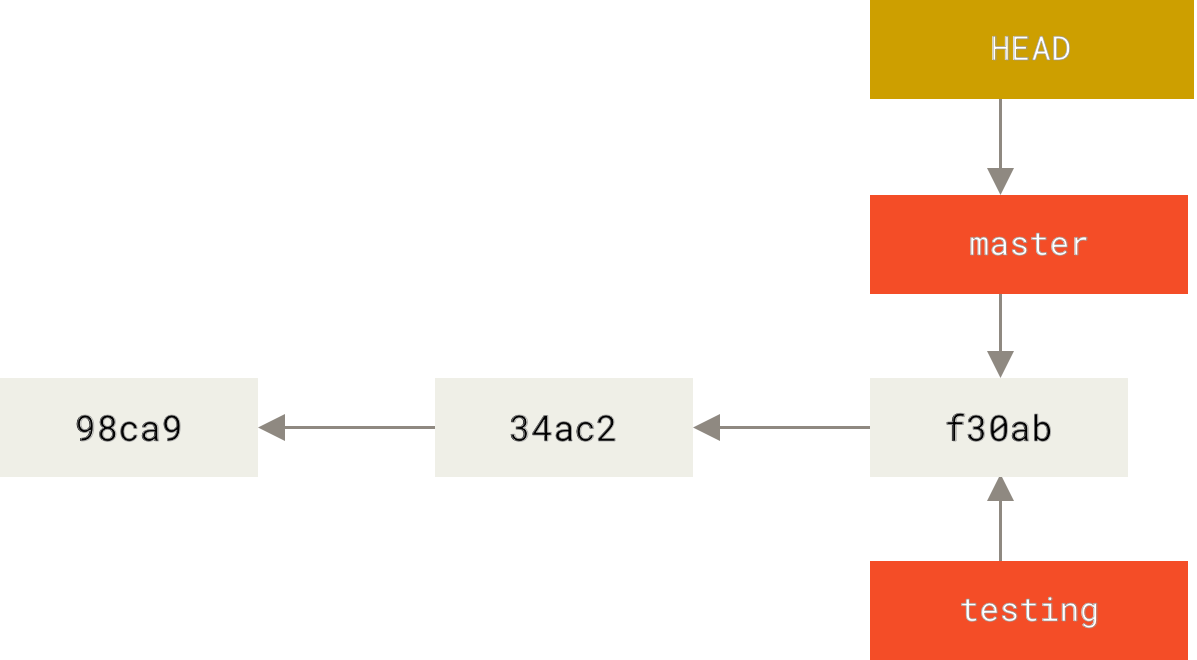
tip
The git branch command only created a new branch:
- It didn’t switch to that branch, e.g.
testing - You’re still on the previous branch, e.g.
master
[!NOTE] How to change to another branch?
- Use
git checkout BRANCH_NAME- Use
git switch BRANCH_NAME
[!WARNING] Be careful when using
git checkoutto switch branch Thegit checkoutcan
- checkout a branch (updates the working tree to match the branch commit)
- checkout files of a branch (update these files in the working tree to match that branch commit)
Patterns when using Git
Gitflow Pattern
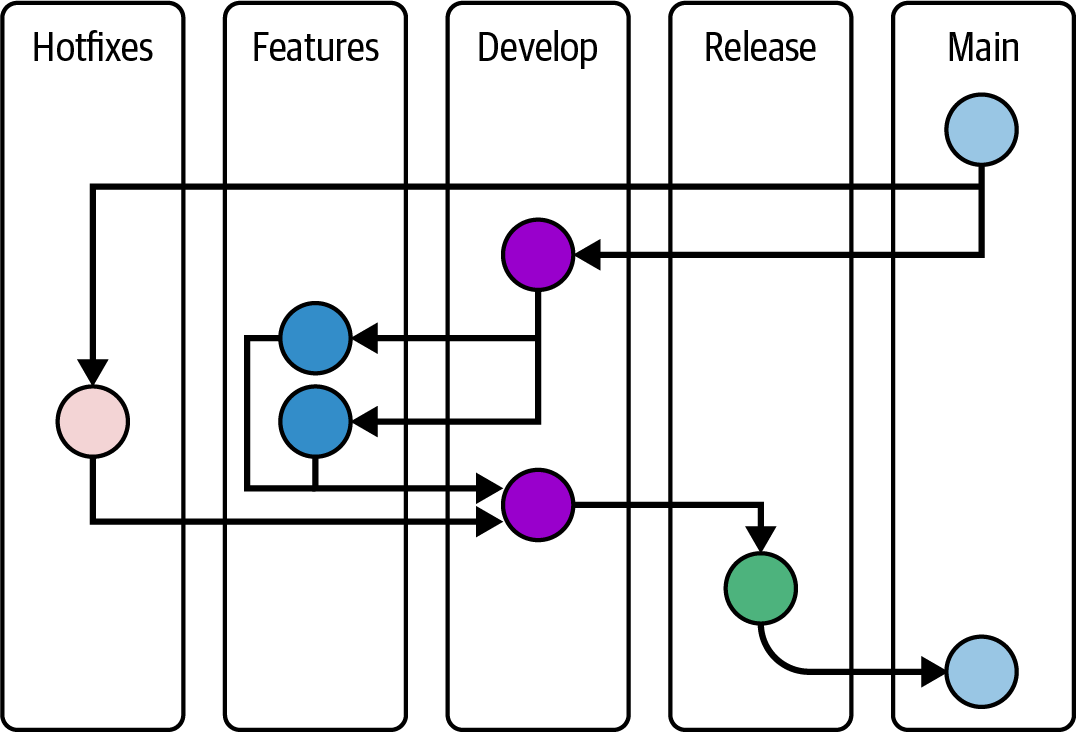
There are several branchs:
- When a
feature/hotfixbranch is finished, it is merge todevelopbranch (the code has been developed) - The
developbranch then merge toreleasebranch to indicate these code is ready to be deployed There may be- a final test round.
- long testing phase with release candidate
During the merging process between branches, there can be one or more layers of approval prior to the merge being allowed.
- These gatekeeping processes ensure quality of code.
- But they also introduce a lot of friction between the development and the production.
Trunk-Based Pattern
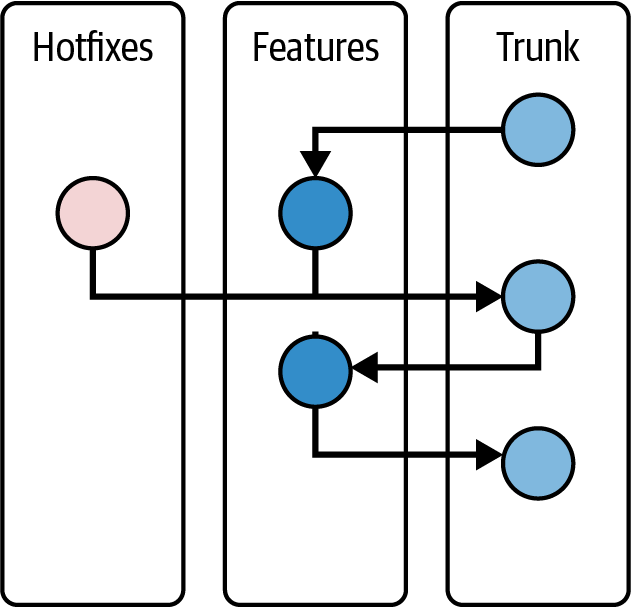
The main idea of trunk-based pattern is to avoid:
- long-running branches
- large merges
by deploying code to production (
trunk) with minimal manually checks and a lot of automating test.
Testing Code
Most of the time, the requirements only include functional one. The non-functional requirements, e.g.
- security
- speed may be in the SLA - service-level agreement.
Unit Testing
unit testing : test in small unit - e.g. function level, small pieces of code : ~ without external dependencies
The main goal of uniting testing:
- ensure the unit work as expected
- maintain code standard
- 100% code coverage
Ideally, all unit tests should be executed in an automated manner.
Integration Testing
integration test : test together units of code : ensure they works together
System Testing
system test : combine all components in an environment as close as possible to the production environment : test both functional & non-functional requirements
Automating Tests
Automation is a key factor in determining the success of a DevSecOps team. There are a lot of tools that help automating testing of code, e.g. Selenium, Python binding to Selenium…
Retrieving a page using Selenium, Python and Firefox
You can run Python code to execute Selenium test that use a headless browser (e.g. Firefox) to:
- capture the screenshot of a site
- crawl a site e.g. Basic Python code to retrieve a web page and capture the result as a screenshot and as a page source
#!/usr/bin/env python
from selenium import webdriver
proto_scheme = "https://"
url = "www.braingia.org"
opts = webdriver.FirefoxOptions()
opts.add_argument('--headless')
driver = webdriver.Firefox(options=opts)
driver.implicitly_wait(10)
driver.get(proto_scheme + url)
driver.get_screenshot_as_file('screenshot.png')
result_file = 'page-source_' + url
with open(result_file,'w') as f:
f.write(driver.page_source)
f.close()
driver.close()
driver.quit()
- Execute the Python code
python3 program.py
# or
# ./program.py
Retrieving text with Selenium and Python
copyright = driver.find_element("xpath", "//p[contains(text(),'Copyright')]")
print(copyright.text)
Summary
- When developing, try to
- be intentional & deliberate
- know why using a pattern, a line of code
- Git and git patterns: gitflow, trunk-based
- Three levels of testing and automation test.